Elementi del linguaggio
Tutti gli elementi che scriviamo nel codice di SuperCollider (lettere, parole, numeri, simboli) sono oggetti.
2 // e' un oggetto 3.56 // e' un oggetto ''ciao'' // e' un oggetto \miao // e' un oggetto b // e' un oggetto SinOsc // e' un oggetto Rand(1,3).postln // sono due oggetti
Ogni singolo oggetto corrisponde a un tipo di dato definito, ovvero viene interpretato dal software in base a una propria identità.
2 // e' un int (numero intero) 3.56 // e' un float (numero decimale) ''ciao'' // e' una stringa \miao // e' un simbolo $b // e' un char SinOsc // e' una UGen Rand(1,3).postln // 'Rand' e' una Classe con due argomenti, invocata con il metodo '.postln'
Le identità che hanno una rappresentazione sintattica diretta, o meglio gli elementi minimi costitutivi del linguaggio di SuperCollider si chiamano literals. Nella lingua parlata potremmo paragonarli a soggetto, verbo, complemento, preposizione, etc. In italiano ad esempio se vogliamo chiedere a qualcuno di compiere un’azione dobbiamo inanellare questi elementi in una frase:
soggetto verbo articolo complemento aggettivo ’’LUIGI SUONA UN DO PIANO!’’
Per comunicare con SuperCollider è necessario fare la stessa cosa, ovvero chiedergli di compiere delle azioni attraverso un linguaggio a lui comprensibile:
// Crea e suona immediatamente un oscillatore sinusoidale con:
// una frequenza random tra 897 e 1345Hz,
// una fase iniziale a 0
// un'ampiezza random tra 0 e 0.5
{SinOsc.ar(rrand(897,1345),0,rand(0.5))}.play(s);
Come possiamo osservare il linguaggio da utilizzare per comunicare con SuperCollider è decisamente meno prolisso dell’italiano. Per prima cosa vediamo dunque quali sono i Literals principali.
Literals
I neofiti e chi vuole arrivare rapidamente a una realizzazione musicale possono saltare momentaneamente la lettura di questo paragrafo passando direttamente al successivo, o meglio leggerlo velocemente tralasciando la piena comprensione o l’esercizio mnemonico, a patto di tornarci in seguito, quando la pratica informatico-musicale e sintattico-lessicale di SuperCollider sarà più ampia. Come altri parti di questo scritto, può essere utilizzato come reference.
Numeri
I numeri corrispondono a un sistema di notazione posizionale, sono colorati in viola e possono essere rappresentati in diversi modi.
Integers. Numeri interi (integer), composti da una o più cifre, sia positivi che negativi.
Floats. Numeri con uno o più decimali (float), positivi o negativi, supportano anche la notazione esponenziale ovvero una combinazione di base ed esponente, più comoda nel rappresentare numeri con molti decimali oppure con molte cifre. Il π può essere scritto ’pi’ e nell’esecuzione riporta il valore corretto.
- Scale degrees. Se utilizziamo numeri interi come gradi di una scala (una possibilità che vedremo più avanti), possiamo usare le lettere s per i diesis e b per i bemolli. Se una cifra segue queste lettere significa frazioni di tono (cents).
// int
8;
-1254;
// float
2.763;
-0.26536;
// notazione esponenziale;
1.5e2; // e2 = 1.5 * 100
1e 4; // e 3 = 1 * 1000
// e + numero di 0 dopo l'uno del moltiplicatore
// pi greco:
pi;
2pi;
0.5pi;
0.25pi;
Characters
I caratteri (characters) sono un unità simbolica corrispondente a un grafema (le singole lettere), sono preceduti dal segno $ e sono di colore verde scuro. In SuperCollider come vedremo possiamo usare le lettere singole senza farle precedere da questo simbolo (ad esempio nelle variabili globali), ma se per caso volessimo identificare un tasto sulla tastiera del computer dovremmo utilizzare un character.
Symbols e Strings
Se una parola in SuperCollider è inclusa tra apici o tra virgolette assume tipi di data differenti, nel primo caso diventa un symbol, nel secondo una string.
I simboli (symbols) sono inclusi tra apici (le virgolette singole) e sono di colore verde. Possono includere numeri, lettere o simboli grafici. Nel caso includano parole, esse sono computate come singola unità, ovvero per SuperCollider ’ciao’ è un solo dato e non quattro char. Nel caso invece includano uno o più numeri (’143.12’), essi diventano un simbolo e non li potremo utilizzare per effettuare operazioni matematiche. Se composti di una sola parola o un solo numero (senza spazi) possono essere scritti sostituendo l’inclusione tra apici con un \ (backslash).
'2'; // e' un symbol, non un int 2+2; // effettua l'operazione '2'+'2'; // non esegue la somma 'ciao' // e' un unico dato 'ciao'+'ciao'; '3.546'; // e' un symbol, non un float 'x'; // e' un symbol non un char 'ciao ciao'; // puo' contenere uno spazio 'AcciPicchia';// puo' contenere maiuscole \2; // se di una sola lettera o parola \ciao; // si puo' scrivere anche cosi' \ciao \ciao; // da' errore...
Le stringhe (strings) sono incluse tra doppie vigolette e sono di colore grigio. Possono includere numeri, lettere o simboli grafici. Nel caso siano parole o numeri con più di una cifra non sono considerati un singolo dato, ma una sequenza di lettere o cifre. Se più stringhe sono adiacenti si combinano in un’unica grande stringa.
"ciao" // e' considerato come "c i a o" "874.23" // e'considerato come "8 7 4 . 2 3" "Questa e' una stringa"; "Anche" " questa" " e'" "una" " Stringa";
Backslash
Come in numerosi linguaggi tra i quali Java e C il simbolo \ (backslash) identifica gli escape character. In SuperCollider è usato principalmente in tre modi:
- per definire l’inizio di un symbol come abbiamo già visto,
\ciao
- per inserire in un testo dei simboli da non stampare come \n che significa newline (vai a una nuova riga), oppure \t che significa tab o tabulatore, etc.
- per inserire caratteri speciali in un testo come le doppie virgolette all’interno di una string: ”Lei mi disse \”ciao\”, e
se ne andò via”. Se però lo usiamo all’interno di una string o di un symbol e non è seguito da nessun escape character SuperCollider
lo ignora. Se scriviamo ad esempio:
"C:\Users\Somebody\SuperCollider"
SuperCollider lo interpreta erroneamente come:C:UsersSomebodySuperCollider
In questo caso dobbiamo scriverlo due volte, la prima definirà il tipo di data, la seconda il simbolo:"C:\\Users\\Somebody\\SuperCollider"
Identifier
I nomi delle variabili e dei metodi cominciano obbligatoriamente con lettere minuscole e si chiamano identifier (identificatori). Devono essere formati da una sola parola e possono contenere il simbolo _ (underscore).
12.postln // int (12) e metodo (.postln) (var ciao_ciao_mare) // variabili e underscore
Classi e UGens
I nomi delle Classi e delle UGens cominciano obbligatoriamente con lettere maiuscole e sono di colore blu.
Object Point Synth SinOsc Pan2
Vedremo in seguito le caratteristiche di questi oggetti in quanto la trattazione di questo argomento richiede ampio spazio.
Valori speciali
I valori speciali che riguardano la matematica booleiana sono scritti come parole (true, false). La parola speciale nil significa vuoto. Sono di colore blu.
a = true // vero b = false // falso c = nil // vuoto
Literal array
Vedremo gli array nel dettaglio ed a lungo nei prossimi capitoli per ora pensiamoli come ad un insieme di numeri inclusi tra due parentesi quadre. I literal array sono degli array preceduti dal simbolo # (cancelletto), che ’blocca’ il contenuto dell’array, ovvero se mettiamo un cancelletto davanti a un array non potremo più modificarne il contenuto. A livello computazionale sono molto più veloci da calcolare che non gli array normali.
[1, 2, 'abc', "def", 4] // array normale: posso modificare
// dinamicamente il contenuto nel corso
// della computazione
#[1, 2, 'abc', "def", 4] // literal array: non posso modificarne
// il contenuto in modo dinamico
Tipi di parentesi
Nelle costruzioni sintattiche del linguaggio di SuperCollider gli oggetti sono solitamente ma non necessariamente inclusi tra parentesi tonde, graffe o quadre. Ogni tipo di parentesi ha una propria funzione e nella maggioranza dei casi, definisce il tipo di data che contiene.
( ) // Parentesi tonde -> Blocchi di codice, espressioni o argomenti
{ } // Parentesi graffe -> Funzioni
[ , ] // Parentesi quadre -> Collezioni, Array o Liste
Nel corso dei prossimi capitoli le esploreremo una per una, parallelamente alla costruzione di brevi sequenze musicali. Prima le parentesi tonde che delimitano blocchi di codice o argomenti, poi le graffe, che delimitano le funzioni e infine le quadre che delimitano array o liste.
Parentesi tonde
In SuperCollider possiamo impiegare le parentesi tonde in tre differenti situazioni. Le prime due sono di immediata comprensione mentre la terza potrà essere assimilata appieno solo quando avremo qualche nozione in più riguardo il linguaggio informatico.
Delimitare un blocco di codice per poterlo selezionare ed eseguire più facilmente:
( // doppio click sulla parentesi seleziona l'intero blocco rand(10.0).postln; exprand(0.001,23).postln; rrand(10,20).postln ) // doppio click sulla parentesi seleziona l'intero blocco)
Quando eseguiamo un blocco di codice, l’ordine di esecuzione è quasi sempre dall’alto al basso, da sinistra a destra, riga dopo riga.Definire l’ordine di esecuzione nelle espressioni matematiche. In SuperCollider la precedenza nelle espressioni va da sinistra a destra, opposta a quella dell’ordine aritmetico. E’ sempre consigliabile forzare l’ordine di esecuzione delle espressioni, anche quando sembra superfluo.
5 + 10 * 4; // = 60 5 +(10 * 4); // = 45 (5+ 10)*4; // = 60 (11/4)*2; // = 5.5 11/(4 *2); // = 1.375 (11/4 *2); // = 5.5
Definire gli argomenti (inputs) di una funzione, una UGen o una Classe.
rand(10); // Abstract function SinOsc.ar(440,0,0.2); // UGen Rand(20,30); // Classe
Nel riquadro seguente troviamo un esempio riassuntivo delle tre situazioni appena illustrate.
( // apre un blocco di codice
play{SinOsc.ar(440, 0, // apre gli argomenti di una UGen
(1.0*0.2)+0.01 // ordina esecuzione espressione
) // chiude gli argomenti della UGen
}
) // chiude il blocco di codice
All’interno di parentesi tonde o graffe possiamo definire delle variabili locali. Vediamo cosa sono e a cosa servono.
Variabili locali
Cos’è una variabile? Possiamo pensare una variabile come a una porzione di memoria del computer destinata a contenere dei dati (numeri, caratteri, audio files, synth, tabelle, array, etc.), suscettibili di modifica nel corso dell’esecuzione di un programma. Per poter distinguere la singola porzione di memoria tra le tante, dobbiamo contrassegnarla con un nome (o etichetta o indirizzo). Prima di farlo dobbiamo però dire a SuperCollider che stiamo per compiere quell’operazione, scrivendo la keyword (parola chiave o parola riservata) var (che appare blu e in grassetto) subito dopo la parentesi di apertura, sia essa tonda o graffa.
(
var...; // blocco di codice
)
{var...; } // funzione
Le variabili locali infatti devono essere dichiarate sempre all’inizio di un blocco di codice (parentesi tonde) oppure all’inizio di una funzione (parentesi graffe). Come nomi di variabili in SuperCollider posssiamo usare:
- Una lettera minuscola dalla a alla z ad eccezione della lettera s che è riservata per il Server.
( var a; var b; var c, d, e; // piu variabili su una sola riga separate da ',' )
- Una parola che deve cominciare con una lettera minuscola e non corrispondere a nessuna keyword (var, arg, nil, true, false, etc.).
Al suo interno può contenere anche caratteri alfanumerici (maiuscole, numeri) ma non spazi e caratteri speciali.
( var bpm; var metr0noMo; var alTeZze, du5a1e; )
Come si evince dai codici precedenti, le variabili possono essere dichiarate una per ogni riga (separate da ;) e in questo caso dobbiamo riscrivere ogni volta la keyword var oppure tutte su di una sola riga separate da una virgola (chiudendo la riga sempre con ;). Utilizzare una scrittura o l’altra non cambia nulla, è solo una questione di preferenze personali (quelle che gli informatici chamano ”stile di programmazione”). Ora che le singole porzioni di memoria sono contrassegnate da un nome (etichetta o indirizzo), possiamo allocarle con uno o più dati (assegnazione della variabile).
( var a, bpm, ciao, miao, lao, metro; // dichiarazione a = 92; // assegnazione di un valore ciao = $b; // assegnazione di un carattere miao = "ciao"; // assegnazione di una stringa lao = 92/60; // assegnazione di un risultato metro = TempoClock.new; // assegnazione di un'istanza durs = [1,0.5,3.0]; // assegnazione di un array )
Dichiarazione e assegnazione dei valori di default (iniziali) possono anche essere contestuali (su una o più righe). Anche in questo caso la scelta di una o l’altra sintassi è personale e pressochè identica.
(
var a = 92, // dichiarazione e assegnazione virgola
ciao = $b, // dichiarazione e assegnazione virgola
miao = "ciao", // dichiarazione e assegnazione virgola
lao = 92/60, // dichiarazione e assegnazione virgola
metro = TempoClock.new, // dichiarazione e assegnazione virgola
durs = [1,0.5,3.0]; // punto e virgola (da 'var' fino a qui
) // per SC e' una sola riga)
Dopo aver dichiarato e assegnato i dati a una variabile, possiamo richiamarli nel codice successivo scrivendo solo la lettera o la parola che li contrassegna (nome, etichetta o indirizzo).
(
var a,b,c; // dichiarzione
a = 92; // assegnazioni
b = "ciao";
c = 92/60;
a * 2; // richiama il valore ed esegue l'operazione riportando 184 nella Post window
b.postln; // scrive ''ciao'' nella Post window
(c+3).postln; // 92/60+3 = 4.533
)
Il titolo di questo Paragrafo è ’Variabili locali’ ma cosa significa ’locali’? In SuperCollider ci sono due tipi di variabili: locali e globali (chiamate anche variabili ambientali). Le prime (quelle incontrate finora) sono definite e assegnate all’interno di blocchi di codice (parentesi tonde) o funzioni (parentesi graffe) e sono precedute dalla keyword var. Sono valide solo all’interno delle parentesi entro le quali sono poste e questa loro caratteristica si chiama scope della variabile.
(
var f,metro; // dichiara
f = 23; // assegna
metro = 10; // assegna
f.postln; // richiama
metro.postln; // richiama
)
f.postln; // se eseguiamo questa riga, non riconosce la variabile 'f' perche non e inclusa tra
// le parentesi dove e stata dichiarata e assegnata
(
var pinco = 12;
var pallino = 34.5;
var a = "ciao";
a.postln;
pallino.postln;
pinco.postln;
)
Grazie al fatto di essere locali e di valere solo all’interno dello scope, le stesse lettere o parole possono essere assegnate a valori o dati differenti se all’interno di blocchi di codice o funzioni differenti, anche se racchiusi globalmente in un unico blocco:
(
{var a=100, bum=120; (bum + a).postln}.value;
{var a=123, bum=345; (bum + a).postln}.value
)
In questo caso ad esempio la variabile a nella riga 2 è assegnata a 100, mentre nella riga 3 a 345. Anche se hanno lo stesso nome sono due variabili differenti e indipendenti, in quanto incluse all’interno di due funzioni diverse. Un consiglio riguardo la scrittura delle variabili locali è quello di separare al dichiarazione con l’assegnazione in quanto in alcuni case compere le due operazioni contemporaneamente potrebbe creare problemi. Prima dichiararle e poi assegnarle.
( var a, bpm, ciao, miao, lao, metro; // dichiarazione a = 92; // assegnazione di un valore ciao = $b; // assegnazione di un carattere miao = "ciao"; // assegnazione di una stringa lao = 92/60; // assegnazione di un risultato metro = TempoClock.new; // assegnazione di un'istanza durs = [1,0.5,3.0]; // assegnazione di un array )
Variabili globali e ambientali
Le Variabili globali invece sono generalmente scritte all’inizio del file, al di fuori di eventuali parentesi tonde o graffe. Non bisogna usare la keyword var e se utilizziamo parole come etichette, dobbiamo anteporre il segno ~ (tilde). Possono essere richiamate ovunque in tutto il codice successivo, sia all’interno che all’esterno di parentesi tonde o graffe.
a = 23; // lettere
~metro = 10; // parole
// possiamo richiamarle:
~metro.postln; // sia fuori dai blocchi di codice
(
a + ~metro; // che all'interno di diversi...
)
(
~metro * a; // ...blocchi di codice
)
Ricordiamoci che per dichiarare ed assegnare una variabile dobbiamo eseguire la riga di codice corrispondente. Se nelle variabili locali questa operazione è sottintesa (i blocchi di codice servono proprio a eseguirne il contenuto più facilmente) nelle variabili globali dobbiamo compiere l’operazione separatamente e prima di richiamarle nel codice successivo. Se all’interno di un patch usiamo lo stesso nome sia per contrassegnare una variabile globale che una locale, quest’ultima ha la precedenza all’interno dello scope.
a = 100; // globale
(
var a = 12.5; // all'interno dello 'scope' la variabile
// locale ha precedenza
a.postln // 12.5
)
a.postln // 100
Le righe di codice dove vengono assegnate le variabili (sia locali che globali) sono una prima eccezione all’ordine di esecuzione ’da sinistra a destra’. In questo caso SuperCollider prima esegue tutto ciò che è scritto dopo il simbolo '=' e successivamente lo assegna al nome che sta prima dello stesso simbolo.
Queste variabili sono anche chiamate ambientali (currentEnvironment) perchè tutto il patch è considerato un ambiente di programmazione ed esse sono valide all’interno di tutto quest’ambiente. E’ consigliabile utilizzare le variabili globali (soprattutto le lettere) solo in files semplici. Il valore di una variabile, infatti, è solitamente modificato più volte nel corso dell’esecuzione del codice (riassegnato). Per questo motivo nel caso di algoritmi complessi o in files molto lunghi è facile perdere il controllo su questi aggiornamenti di valore. Se scriviamo ed eseguiamo currentEnvironment in SuperCollider otteniamo informazioni (nella Post window) riguardo le variabili globali già assegnate.
currentEnvironment; // se eseguiamo riporta informazioni sulle variabili gia assegnate
Riassegnazioni
A cosa servono le variabili? principalmente ma non solo, servono a strutturare e rendere il codice più leggibile. Facciamo un esempio. Se volessimo ottenere i risultati di tutte le quattro operazioni matematiche principali su due numeri potremmo scrivere.
(
("somma: "++ (10 + 12)).postln;
("sottrai: "++ (10 - 12)).postln;
("moltiplica: "++ (10 * 12)).postln;
("dividi: "++ (10 / 12)).postln
)
Se eseguiamo l’intero blocco possiamo leggere i risultati nella Post window. E’ un codice corretto, ma nel caso in cui volessimo cambiare i due valori per ottenere altri risultati dovremmo riscriverli quattro volte (due per ogni operazione) e non è decisamente pratico. Se invece decidiamo di assegnarli a due variabili locali:
- ad ogni cambiamento li scriviamo solo una volta invece che quattro
- sappiamo che sono all’inizio del file e non dobbiamo perdere tempo a ricercarli nei meandri del codice (in questo caso il file è corto ed è semplice ritrovere le loro posizioni, ma pensiamo a file lunghi e complessi, la ricerca dei singoli valori potrebbe essere decisamente faticosa).
(
var a = 10, b = 12; // dichiarazione e assegnazione
("somma: "++ (a + b)).postln;
("sottrai: "++ (a - b)).postln;
("moltiplica: "++ (a * b)).postln;
("dividi: "++ (a / b)).postln
)
Per gli stessi motivi le variabili (sia locali che globali) sono molto utili nel caso volessimo separare i valori musicali di alto livello (che potremmo voler modificare più volte per sperimentare cambiamenti musicali) da parti di codice di basso livello che servono solo ad effettuare le operazioni degli algoritmi che utilizziamo per ottenere un risultato musicale. Torneremo spesso su questo argomento.
Ricordando che SuperCollider esegue un blocco di codice dall’alto al basso, riga dopo riga, in un patch le variabili, siano esse locali o globali possono essere riassegnate (sovrascritte) più volte:
( a = 10 + 3; // assegna a.postln; // stampa '13' a = 999; // riassegna, sostituendo il valore precedente a.postln; // stampa '999' )
Sfrutteremo questa caratteristica in diverse situazioni. La più esemplificativa e frequente consiste nell’usare la variabile stessa (solitamente locale) per auto-aggiornarsi creando un contatore:
a = 0; // prima assegnazione a = a + 1; // contatore a = a + 2.5; // passo di 2.5
Ogni volta che eseguiamo la riga 2 il valore assegnato alla variabile a incrementa di 1 mentre se eseguiamo la riga 3 l’incremento sarà di 2.5. Osserviamo questo processo nel dettaglio:
- riga 1: all’esecuzione assegnamo il valore 0 alla variabile a.
- riga 2: alla prima esecuzione calcola 0+1 in quanto a = 0 dalla riga precedente. Successivamente riscrive a con il nuovo valore calcolato (a = 1).
- riga 2: alla seconda esecuzione calcola 1+1 in quanto nell’esecuzione precedente alla variabile a è stato riassegnato il valore 1. Successivamente riscrive a con il nuovo valore calcolato (a = 2).
- riga 2: alla terza esecuzione calcola 2+1 in quanto nell’esecuzione precedente alla variabile a è stato riassegnato il valore 1. Successivamente riscrive a con il nuovo valore calcolato (a = 3).
- riga 2: e via dicendo...
Parentesi graffe (funzioni)
In SuperCollider tutto ciò che è racchiuso tra parentesi graffe è una funzione. Ma cos’è una funzione? Una delle possibili definizioni dice che è un particolare costrutto sintattico che permette di raggruppare al suo interno una sequenza di istruzioni o operazioni che a partire da determinati input restituiscono determinati output.

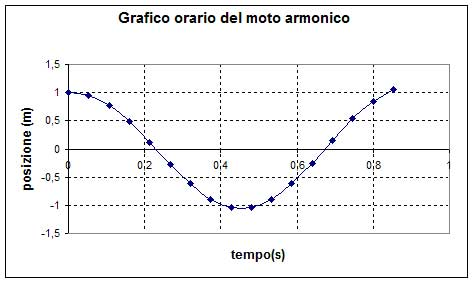
Da questo il nome. I valori in uscita (output) sono ”in funzione” di quelli in entrata (input). Per capire meglio pensiamo alla funzione matematica che descrive una cosinusoide:
y = cos(x)
Ogni volta che modifichiamo il valore x (input) e valutiamo (eseguiamo) la funzione otteniamo un valore y (output) differente.
( cos(0).postln; // y = 1.00000000000000 cos(1).postln; // y = 0.54030230586814 cos(2).postln; // y = -0.41614683654714 cos(3).postln; // y = -0.98999249660045 cos(4).postln; // y = -0.65364362086361 cos(5).postln; // y = 0.28366218546323 )
Se consideriamo i valori in input come ascisse di un piano cartesiano e i valori in output come ordinate, otterremo un grafico che rappresenta una cosinusoide:
Scriviamo ora nell’interprete di SuperCollider la seguente funzione ed eseguiamo il codice.
{2 + 3}
Nella post window non compare il risultato dell’addizione ma una scritta che riporta 'a Function'. Questo perchè una funzione per restituire un risultato in output deve essere valutata da un metodo. Ma cos’è un metodo? I metodi sono istruzioni che diamo agli oggetti di SuperCollider. Seguono il nome e sono separati da quest’ultimi da un punto: oggetto.metodo. Nei codici illustrati finora per esempio abbiamo incontrato spesso il metodo '.postln' la cui funzione è comunicare all’oggetto che lo precede la seguente istruzione: stampa nella post window cosa sei o il tuo valore.
( ((3*2)/4).postln; "ciao".postln; TempoClock(3).postln; 2.postln; [2,34.5,56].postln; SinOsc.ar.postln; )
Torniamo alle funzioni. Uno dei metodi con i quali possiamo valutarle è '.value' che come termine fornisce un duplice ausilio mnemonico: possiamo ricordarlo sia come ’valore’ ovvero ’restituisci il risultato in output di questa funzione’ che come ’vàluta’ ovvero ’vàluta questa funzione e restituisci il risultato in output’.
{2 + 3}.value
La funzione precedente in realtà non ha molto senso in quanto i due elementi che la compongono (inputs) sono dei valori costanti. Avremmo potuto semplicemente scrivere l’operazione e assegnarla a una variabile.
a = 2 + 3;
a.postln;
a.postln; // etc.
a = {2 + 3};
a.value;
a.value; // etc.
Come possiamo osservare variabili e funzioni hanno caratteristiche simili. Questo perchè uno degli scopi principali di entrambe in informatica è quello di rendere più ordinato e comprensibile il codice, ovvero realizzare quella che si chiama formalizzazione di un pensiero. Ci sono però anche alcune differenze tra le quali la più importante e discriminante consiste nel fatto che:
le prime (variabili) servono a richiamare porzioni di codice contenente operazioni ricorrenti i cui valori interni non possono essere modificati dinamicamente dall’esterno al momento in cui sono richiamati,
le seconde (funzioni) servono a richamare porzioni di codice contenenti operazioni ricorrenti i cui valori possono essere modificati dinamicamente dall’esterno (input). Nell’esempio precedente, gli addendi.
Per modificare i valori interni di una funzione dall’esterno, in SuperCollider dobbiamo effettuare quattro operazioni:
- assegnare la funzione in questione a una variabile.
f = {"funzione"}; - dichiarare al suo interno degli argomenti.
f = {arg a, b;}; - definire le operazioni da effettuare sugli argomenti.
( f = {arg a, b; a - b}; ) - eseguire tre operazioni contestuali:
- richiamare la funzione specifica attraverso l’etichetta assegnata alla variabile,
- modificare dinamicamente i valori degli argomenti (inputs)
- valutarla ottenendo il risultato (output).
( f = { // assegna a una varibile arg a, b; // dichiara gli argomenti a - b}; // definisce le operazioni da effettuare ) f.value(5, 3); // richiama, modifica valori e valuta f.value(2.5, 5.1); // etc.
L’elemento nuovo in questo esempio è costituito dagli argomenti. Osserviamoli nel dettaglio.
Argomenti delle funzioni
Possiamo pensare gli argomenti di una funzione come variabili locali alle quali possiamo modificare dinamicamente il valore non solo all’interno del blocco di codice che le contiene (in questo caso lo scope di una funzione) ma anche dall’esterno. Dobbiamo specificarli (dichiararli) all’interno della funzione stessa prima di qualsiasi altra cosa, variabili comprese e possiamo scriverli in due modi differenti ma equivalenti:
(
f = {arg a, b; // preceduti dalla keyword arg.
a / b};
g = {|luigi berenice| // racchiusi tra due simboli |.
luigi * berenice}
)
Nel primo caso dobbiamo separarli con virgole e l’ultimo deve essere seguito da un punto e virgola, nel secondo caso no. Possiamo utilizzare sia lettere che parole a nostro piacere, escludiendo quelle riservate alle keywords.
Dopo aver definito gli argomenti e stabilito quali operazioni devono essere effettuate su di essi possiamo cambiarne i valori dinamicamente utilizzando la seguente sintassi: 'funzione.value(arg1,arg2,arg3,etc.)' dove al posto di arg1,arg2, etc. scriviamo i nuovi valori dei singoli argomenti. Questi ultimi non rimangono in memoria e valgono solo per la valutazione della riga dove sono scritti.
(
f = {arg a, b;
a / b};
g = {|luigi berenice|
luigi * berenice};
f.value(100, 2).postln; // 50
f.value(12, 20).postln; // 0.6
g.value(1.3, 1.2).postln; // 1.56
g.value.postln; // errore
)
All’esecuzione di questo codice SuperCollider prima sostituisce i valori degli argomenti e dopo valuta la funzione restituendone il risultato. Gli argomenti possono essere specificati in due modi diversi:
stile regolare dove il nome è sottointeso e seguono obbligatoriamente l’ordine da sinistra a destra
stile keyword ovvero specificando una keyword corrispondente al nome scelto nella loro dichiarazione all’interno della funzione (sia esso lettera o parola) seguita da ’:’ e dal nuovo valore. L’ordine può essere a piacere e non necessariamente andare da sinistra a destra.
(
f = {arg acci, bicci; acci / bicci}; // funzione
f.value(10, 2).postln; // stile regolare
f.value(bicci: 2, acci: 10).postln; // stile con keywords
)
Così come per le variabili, possiamo anche assegnare valori di default agli argomenti che non saranno sovrascritti da eventuali nuovi valori, ovvero saranno sostituiti solo nella singola valutazione.
(
f = {arg a = "luigi ", b = "e berenice";
a++b};
g = {|luigi = 12 berenice = 34.5|
luigi * berenice};
f.value("gina", " e brisotto").postln; // gina e brisotto
f.value.postln; // luigi e berenice
g.value(3,5).postln; // 15
g.value.postln // 415
)
All’interno di una funzione dopo gli argomenti possiamo specificare anche variabili (locali) che si comportano nel modo che abbiamo già visto. Siccome in alcune situazioni è necessario prima dichiarare i nomi di argomenti e variabili locali e dopo assegnargli valori di default, consiglio di utilizzare sempre questo schema sintattico.
(
f = {arg a, b; // dichiaro argomenti (input)
a = 100; // valori di default
b = 12;
var piu, meno, diviso, per; // dichiaro variabili locali
piu = a + b, // assegno le operazioni
meno = a - b,
diviso = a / b,
per = a * b;
["somma: "++piu, // stampa output
"sottrazione: "++ meno,
"divisione: "++ diviso,
"moltiplicazione: "++ per].postln
}
)
f.value(2, 3); // modifico dinamicamente
Riassumendo. Se vogliamo modificare valori dall’esterno di una funzione richiamata più volte nel corso della computazione (input) utilizzeremo argomenti. Se invece le modifiche restano confinate al suo interno (scope), utilizzeremo variabili locali. Possiamo passare argomenti a una funzione, valutarla e ottenere il risultato (output) invocando il metodo '.value' nella seguente forma sintattica: funzione.value(arg1,arg2,etc).
Funzioni astratte
In SuperCollider abbiamo a disposizione due modi per scrivere alcune funzioni di uso comune:
- racchiuderle tra due parentesi graffe e utilizzare la sintassi che abbiamo visto nel paragrafo precedente (custom functions).
- utilizzare una Classe che si chiama AbstractFunction (funzioni astratte).
5.reciprocal // Reciproco
r = {|a| 1/a};
r.value(5);
5.squared; // Quadrato
f = {|a| a*a};
f.value(5);
0.5.ampdb; // Conversioni, etc.
f = {arg a; 20*(log10(a))};
f.value(0.5);
Una funzione astratta è un oggetto che risponde a una serie di messaggi che rappresentano alcune funzioni matematiche usate frequentemente. Nel codice precedente ad esempio:
- '.reciprocal' effettua l'operazine 1/n,
- '.squared' calcola il quadrato e
- '.ampdb' calcola la conversione da ampiezza lineare in decibels (dB)
Possiamo trovare l’elenco di tutte le funzioni astratte che abbiamo a disposizione in SuperCollider nell’Help file di AbstractFunction. Se leggiamo attentamente questo Help possiamo notare che le AbstracFunctions sono suddivise in tre tipologie che variano a seconda del numero di argomenti (o messaggi) che accettano:
Unary Messages (messaggi unari). Sono quelle funzioni nelle quali possiamo specificare un solo argomento. In SuperCollider si chiamano anche UnaryOpFunction.
5.reciprocal // Reciproco 5.squared; // Quadrato 0.5.ampdb; // Conversioni, etc. -3.abs; // Valore assoluto 25.sqrt; // Radice quadrata (square root) 60.rand; // Scelta pseudocasuale (tra 0 e n-1), etc.
Binary Messages (messaggi binari). Sono quelle funzioni nelle quali possiamo specificare due argomenti come ad esempio le operazioni matematiche. In SuperCollider si chiamano anche BinaryOpFunction.
3 + 2; // Operazioni matematiche 2 > 7; // Operazioni booleiane round(1.2357, 0.1); // Approssimazione decimale rrand(1.0, 23.5); // Scelta pseudocasuale (tra min e max) exprand(1, 800); // Distribuzione random non lineare, etc.
Messages with more arguments (messaggi Nnari). Sono quelle funzioni nelle quali possiamo specificare più di due argomenti come ad esempio il clipping dove dobbiamo specificare un minimo, un massimo e il valore da verificare. In SuperCollider si chiamano anche NAryOpFunction.
13.clip(1, 10); // Clipping 13.wrap(1, 10); // Wrapping (modulo) 13.fold(1, 10); // Folding (speculare)
Differenze
Osserviamo una importante differenza tra funzioni e funzioni astratte. Eseguiamo il seguente codice:
rand(100); // riporta ad ogni esecuzione un valore pseudo-casuale tra 0 e 100.
{rand(100)}; // riporta "a Function" e deve essere valutata
{rand(100)}.value;
Notiamo che le funzioni astratte non hanno bisogno del metodo '.value' per restituire il risultato, mentre le funzioni incluse tra parentesi graffe si. Le conseguenze di questa differenza sono illustrate nel codice seguente:
dup( rand(100), 5); // a ogni esecuzione sceglie un numero pseudo-casuale e lo ripete 5 volte uguale...
dup({rand(100)}, 5); // a ogni esecuzione ripete 5 volte la funzione di scegliere un numero pseudo-casuale...
Se replichiamo n volte una funzione astratta ne replichiamo il risultato, mentre se replichiamo n volte una funzione inclusa tra parentesi graffe ne replichiamo il processo interno.
Notazioni
Se osserviamo attentamente il codice di esempio sui messaggi binari possiamo notare che in alcuni casi il messsaggio che diamo all’oggetto non segue la sintassi che conosciamo 'oggetto.metodo(arg)'. Manca il punto e un oggetto al quale inviare il messaggio, o meglio questo oggetto diventa parte integrante degli argomenti, per la precisione il primo. Questo perchè in SuperCollider per inviare messaggi a un oggetto abbiamo a disposizione due possibili notazioni che si equivalgono: receiver notation e functional notation.
23.rand; // Receiver notation rand(23); // Functional notation
Receiver notation
E’ la notazione che segue lo schema sintattico incontrato finora. Il messaggio segue l’oggetto, separato da un punto e può avere uno o più argomenti racchiusi tra parentesi tonde.
124.postln;
100.rand;
(Env.new([0,1,0.5,0],[0.1,0.2,1])).plot;
({SinOsc.ar(543,0,0.25)}).play;
("notazione ricevente").speak;
Functional notation
L’oggetto diventa il primo argomento del messaggio e il punto sparisce.
postln(124); // stampa nella post window
rand(100); // sceglie un valore random tra 0 e 100
plot(Env.new([0,1,0.5,0],[0.1,0.2,1]));
play({SinOsc.ar(543,0,0.25)});
speak("notazione funzionale"); // Solo Mac
Praticamente tra le due notazioni non c’è alcuna differenza. Se prendiamo come esempio l’azione di stampare un oggetto nella post window (postln) possiamo pensare la prima come: oggetto.stampami e la seconda come: stampa(questo oggetto). In determinati casi il codice è più comprensibile se ne utilizziamo una, in altri l’altra. Teoricamente la receiver notation richiama un metodo programmato in precedenza all’interno di una Classe mentre la functional notation invia un messaggio a un oggetto dall’esterno come nel caso delle funzioni (AbstractFunction). Notiamo che la richiesta di compiere un’azione fatta a un oggetto può chiamarsi sia messaggio (quando utilizziamo la functional notation) che metodo (quando utilizziamo la reciver notation). Ai fini pratici sono sinonimi.
Nesting
Possiamo anche invocare due o più metodi sullo stesso oggetto.
Routine({ 1.wait; "ciao".postln; 1.wait; "ciao".postln}).reset.play;
Questo tipo di costrutto sintattico si chiama nesting ("a nido d’ape") e rappresenta una delle una delle maggiori potenzialità di SuperCollider: ogni oggetto può diventare diventare argomento di altri oggetti, come un insieme di scatole cinesi o matrioske. L’esempio seguente è scritto interamente in functional notation ed estremamente esemplificativo al riguardo.
10; // un numero
rand(10.0); // random
dup({rand(10.0)}, 8); // replica
sort(dup({rand(10.0)}, 8)); // ordina
round(sort(dup({rand(10.0)}, 8)), 0.01); // arrotonda
postln(round(sort(dup({rand(10.0)}, 8)), 0.01)); // stampa
plot(postln(round(sort(dup({rand(10.0)}, 8)), 0.01))); // visualizza
Possiamo anche utilizzare la receiver notation ricordando che il codice su una riga viene eseguito quasi sempre da sinistra a destra fino al punto e virgola.
10.0; // un numero
10.0.rand; // random
10.0.rand.round(0.01); // arrotonda
{10.0.rand.round(0.01)}.dup(8); // replica
{10.0.rand.round(0.01)}.dup(8).sort; // ordina
{10.0.rand.round(0.01)}.dup(8).sort.postln; // stampa
{10.0.rand.round(0.01)}.dup(8).sort.postln.plot; // plot
Ricordiamo che la scelta di una o dell’altra notazione (come già enunciato nel paragrafo dedicato all’argomento) è esclusivamente personale, da compiere tenendo sempre ben presente che un codice "pulito" e chiaramente leggibile deve essere il fine da perseguire.
Organizzazione del codice
Seguendo quest’ultima indicazione proviamo a rendere ancora più leggibile il codice precedente assegnando ogni passaggio a variabili i cui nomi (etichette o indirizzi) possano assumere valenza mnemonica riguardo al tipo di richiesta fatta all’oggetto.
(
var nelementi,range,valori,lista,ordina,semplifica;
nelementi = 8; // variabili locali (input)
range = 100.0;
valori = {rand(range)}; // algoritmo
lista = dup(valori, nelementi);
ordina = sort(lista);
semplifica = round(ordina,0.01);
// risultati (output)
semplifica.postln; // stampa
semplifica.plot; // visualizza
)
Come possiamo notare il blocco di codice è inoltre suddiviso idealmente in quattro parti che ricordano lo schema delle funzioni.
- all’inizio dichiariamo tutte le variabili locali. Questa operazione ci aiuta a "raccogliere" le idee e a focalizzare quali sono i parametri necessari a perseguire il nostro scopo.
- in seguito assegnamo i valori a tutti i parametri di alto livello che potremmo voler modificare in seguito per sperimentare differenti risultati musicali. Questa collocazione ci permette di avere un accesso immediato alle parti di codice che presumibilmente dovremo ricercare e che saranno maggiormente modificate nel corso della programmazione o della composizione musicale.
- dopodichè specifichiamo le operazioni di basso livello (algoritmo) assegnandole a variabili o meno.
- infine scriviamo le istruzioni che riportano il risultato delle operazioni precedenti.
Se cambiamo il range dei valori numerici l’esempio precedente può assumere valenza musicale, ovvero se il range entro il quale scegliere i valori random diventa da 0 a 12 e se sommiamo ai valori ottenuti un offset di 60 possiamo ottenere una sequenza di n altezze assimilabile a midi pitch compresi tra il do3 (do centrale valore 60) e il do4 (un ottava sopra valore 72 ovvero 60 + 12).
plot(postln(round(sort(dup({60 + rand(12.0)}, 8)))));
Come vedremo nei prossimi Capitoli questo tipo di organizzazione del codice può avere numerosi parallelismi e similitudini con l’organizzazione di una partitura musicale, il che facilita la ricerca di quel terreno comune tra i due linguaggi illustrato nel paragrafo iniziale. Infine quando affronteremo i segnali audio, il nesting e l’organizzazione del codice saranno fondamentali nell’effettuare collegamenti (plugs) tra segnali nella generazione di algoritmi di sintesi e elaborazione del suono. Di seguito un esempio.
(
s.waitForBoot{
play(
{
CombN.ar(
SinOsc.ar(
midicps(
LFNoise1.ar(3, 24,
LFSaw.ar([5, 5.123],
0, 3, 80)
)
),
0, 0.4),
1, 0.3, 2)
}
)}
)
// Piu' ordinato e comprensibile:
(
s.waitForBoot{
{var sawfreq,freqHz,freqcps,sine,filtro;
sawfreq = LFSaw.ar([5, 5.123], 0, 3, 80); // Onda a dente di sega
// tra 77 e 83 con
// frequenza di 5 Hz
freqHz = LFNoise1.ar(3, 24, sawfreq); // cambia l'offset
freqcps = freqHz.midicps; // Hz --> cps
sine = SinOsc.ar(freqcps,0,0.4); // Oscillatore sinus
filtro = CombN.ar(sine,1, 0.3, 2); // Comb filter
filtro}.play}
)