Scheduler e post window
In informatica attivare automaticamente determinati processi o eventi in una sequenza temporale è un compito gestito da una parte del sistema operativo chiamata scheduler. Attraverso il processo di scheduling possiamo temporizzare una lista di eventi o far eseguire al software alcune operazioni prima di altre ad un tempo estremamente rapido. La velocità di computazione non temporizzata dipende dalla quantità di operazioni che il computer deve effettuare e dalle sue caratteristiche tecnico costruttive.
Facciamo attenzione a non confondere il tempo di scheduling con la sample rate (il tempo della computazione dei segnali audio digitali). In SuperCollider il primo è proprio dell’Interprete (sclang) e la sua velocità può variare a seconda di diversi fattori non sempre predicibili tra cui ad esempio il modello di computer utilizzato, mentre la seconda è propria del Server (scsynth) e nel momento in cui è stabilita è uguale su tutti i computers.
Per meglio comprendere lo scheduling in SuperCollider, calcoliamo le seguenti conversioni temporali eseguendo il codice una riga alla volta oppure selezionando l’intero blocco incluso tra le parentesi tonde.
( 82 / 60; // conversione bpm --> bps: bpm/60. 1.3 * 60; // conversione bps --> bpm: bps*60. 82 / 60000; // conversione bpm --> ms: 60000./bpm 82 / 60; // conversione bpm --> s: 60./bpm 1/2; 1/3; 1/4; )
Possiamo notare come ad ogni esecuzione il risultato viene stampato nella Post window. Se procediamo una riga alla volta possiamo scegliere l’ordine andando su e giù tra le righe col cursore, mentre se eseguiamo l’intero blocco di codice vedremo postati i risultati nello stesso ordine delle operazioni scritte nell’Interprete, riga dopo riga, dall’alto verso il basso. Quando eseguiamo il codice, i risultati delle operazioni sono scritti nella Post window, infatti questo è lo spazio dove possiamo leggere o scrivere dati e informazioni utili riguardo ciò che stà accadendo in SuperCollider. Il monitoraggio dello scheduling ne è un tipico esempio. La Post window diventa inoltre uno strumento indispensabile anche quando dobbiamo effettuare un debugging, ovvero cercare e correggere eventuali errori presenti nel codice. Per verificare eseguiamo le seguenti righe:
(
var freq;
freq = rrand(300,600);
{SinOsc.ar(freq,0,0.2)}.play;
)
Se abbiamo già fatto il Boot dell’audio (cmd+b), vedremo postato qualcosa riguardo a un Synth (un’insieme di informazioni che potrebbero tornare utili).
Synth(”temp_0” : 1000)
Se invece le eseguiamo senza aver fatto il Boot (se già acceso fare prima ”Quit Server”), comparirà il seguente messaggio di errore:
RESULT = 0 WARNING: server ’localhost’ not running. nil
Quando SuperCollider incontra un errore nella compilazione del codice, oltre a non funzionare (nel migliore dei casi) stampa nella Post window un messaggio di errore e indica con una freccia o un pallino il punto esatto dove si è interrotta la compilazione. Attenzione, non dove si è verificato l’errore, ma dove si è fermato. Sapendo che l’esecuzione avviene dall’alto al basso, riga dopo riga, quasi sempre da sinistra a destra, probabilmente l’errore è poco prima e a noi non resta che compiere le verifiche del caso per trovarlo. Un altro esempio:
play({SinOsc.ar(LFNoise0.kr(12,mul:600,add:1000)0.1)}); //...manca una virgola...
La maggior parte delle volte si tratta di errori di battitura (manca una virgola, non abbiamo chiuso una parentesi, abbiamo usato una lettera maiuscola dove non potevamo, etc.) ma altre volte è possibile imbattersi in situazioni più complesse da risolvere. Per questi e altri casi, possiamo consultare i messaggi di errore più comuni sul sito di Daniel Nouri.
Controllo del tempo
Ora che abbiamo compreso il processo di scheduling, prima di cominciare a pensare quali possono essere le possibilità di controllare il tempo in SuperCollider vediamo quali sono i parametri che utilizzeremo per misurare e controllare il tempo e adottiamo a-criticamente la seguente regola (non necessariamente valida ma che al momento può aiutarci a comprendere meglio):
una riga di codice = un singolo evento (onset e durata) nel tempo
(sia esso una nota, una pausa, un trigger, il play di audio file, un grano di una sintesi granulare, etc.) Seguendo questo assunto il codice seguente descrive cinque eventi in successione:
( "riga uno -> primo evento".postln; "riga due -> secondo evento".postln; "riga tre -> terzo evento".postln; "riga quattro -> quarto evento".postln; "riga cinque -> quinto evento".postln; )
Al momento dell’esecuzione la computazione sarà ordinata (sequenziata) ma molto veloce, quasi contemporanea all’azione delle dita sulla tastiera del computer. Non abbiamo alcun tipo di controllo sul tempo e come abbiamo detto in precedenza, la velocità di esecuzione dipenderà dalle caratteristiche dell’hardware e dalla mole di dati che devono essere computati. Una possibile trascrizione musicale è illustrata nella figura sottostante, dove i righi del pentagramma non indicano le altezze musicali, ma le righe dell’Interprete.

In musica abbiamo però la necessità di poter controllare sequenze di eventi nel tempo in diversi modi, con diversi parametri e unità di misura, non basta inanellarli in un ordine più o meno consequenziale. Dobbiamo avere ad esempio la possibilità di modificare i Tempi Delta che intercorrono tra una riga di codice (evento) e quella successiva o di controllare (idealmente) la durate delle operazioni effettuate nella computazione interna alle righe di codice, come illustrato nella figura seguente.

Per farlo dobbiamo utilizzare due Classi dedicate di SuperCollider: Routine e Task.
Routine
Secondo l'assunto appena esposto, il codice seguente specifica una sequenza di cinque eventi in rapidissima successione dall’alto al basso, riga dopo riga, da sinistra a destra.

( "riga uno -> primo evento".postln; "riga due -> secondo evento".postln; "riga tre -> terzo evento".postln; "riga quattro -> quarto evento".postln; "riga cinque -> quinto evento".postln; )
Immaginiamo ora di volere stoppare automaticamente la computazione alla fine di ogni riga, come se ci fosse una fermata musicale (corona o punto coronato) e di dover compiere una nuova azione per riprendere la valutazione del codice da dove si è fermata:
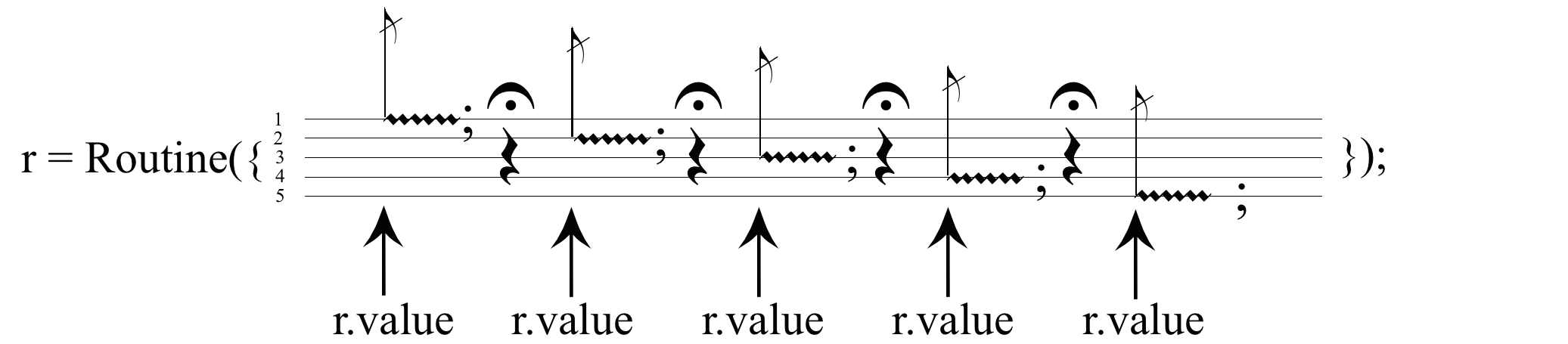
Questo è quello che fanno le Routine. Per verificarlo eseguiamo l’esempio nel box seguente. Prima le righe da 1 a 9 e poi la riga 10 oppure la 11, più volte.
(
r = Routine.new({ // Assegno la Routine alla variabile globale 'r'
1.yield; // yield = fermata
2.wait; // wait = sinonimo di yield
3.yield;
4.yield;
5.yield;
})
)
r.value; // valuta riga per riga
r.next; // sinoinimo di .value
r.reset // riporta all'inizio
Risulta evidente che lo schema sintattico delle Routine è simile a quello della maggior parte delle Classi che hanno una funzione come primo argomento:
Routine.new( {func} );.
Analizziamo brevemente ma nel dettaglio i metodi utilizzati nel codice precedente.
.new crea una nuova istanza di Routine. E’ generalmente sottinteso.
.yield indica la fermata, è sempre posto alla fine di una riga e ha un sinonimo (.wait). Possiamo utilizzare il primo solo all’interno di una Routine mentre il secondo anche in altri costrutti sintattici. Se vogliamo ulteriori informazioni su queste differenze possiamo richiamare gli Help files di questi due metodi. Richiamando l’Help file di un metodo nel modo usuale (cmd+d) compare la seguente schermata:
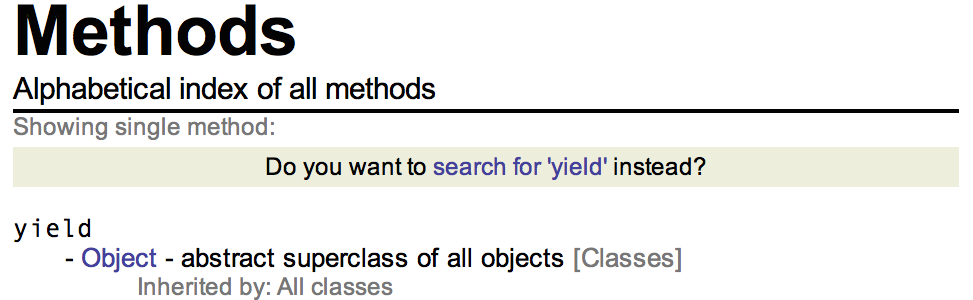

Possiamo vedere che sono indicate tutte le tipologie di oggetti sui quali il metodo può essere invocato. Quelli cancellati con una riga sono obsoleti o non documentati.
.value computa il codice all’interno della Routine fino a quando non incontra uno dei due metodi precedenti. In quel caso interrompe la computazione e per farla ripartire da dove si è fermata dobbiamo nuovamente invocarlo. Anche questo metodo (quando invocato su di una Routine) ha un sinonimo: .next. Nell’esempio precedente sono specificate cinque fermate. Ogni qualvolta eseguiamo la riga 10 o la 11 SuperCollider stampa nella post window l’oggetto al quale inviamo il messaggio .yield o .wait (che in questo caso sono numeri interi). Dopo cinque valutazioni la Routine restituisce nil in quanto il suo contenuto è stato letto interamente e nel caso volessimo eseguirla nuovamente dovremmo prima invocare su di essa il metodo .reset.
.reset riporta la Routine al suo stato iniziale rendendo possibile una nuova esecuzione da capo a fondo.
Invece che richiamare il contenuto di una Routine un passo alla volta con il metodo .value, possiamo automatizzare l’esecuzione dell’intera sequenza (sequencing) invocando sulla Routine il metodo .play.
(
r = Routine({
0.5.yield; // tempo delta in secondi (fermata)
"trig_1".postln; // evento
2.yield;
"trig_2".postln;
0.1.yield;
"trig_3".postln;
});
)
r.reset.play; // Esegue la Routine
In questo caso se scriviamo numeri int o float come oggetti sui quali invocare .yield o .wait all’interno della Routine, questi vengono interpretati da SuperCollider come tempi delta di attesa prima di passare oltre (le fermate o corone musicali di cui sopra). Per il momento i valori numerici specificati all’interno della Routine equivalgono a secondi.
Se vogliamo fermare lo scheduling di una Routine possiamo farlo utilizzando due comandi differenti:
- fermando tutta la computazione di SuperCollider manualmente nel modo usuale (cmd + .)
- assegnando la Routine a una variabile per poi invocare il metodo .stop
( r = Routine({ // definiamo una Routine 0.5.yield; "trig_1".postln; 2.yield; "trig_2".postln; 2.yield; "trig_3".postln; 2.yield; "trig_4".postln; }); ) r.play; // eseguiamo r.stop; // stoppiamo prima che finisca r.reset.play; // eseguiamo nuovamente da capoAnche in questo caso, se volessimo rieseguire da capo la Routine dopo aver fermato la computazione in questo modo, dovremmo "resettarla" con i comandi .reset.play().
Abbreviazioni
Per scrivere una Routine possiamo utilizzare anche un’abbreviazione sintattica invocando il metodo .fork() su di una funzione.
(
{
"trig_1".postln; // azione (evento o nota)
1.wait; // aspetta 1 secondo
"trig_2".postln;
1.wait;
"trig_3".postln;
}.fork // equivale a '.play'
)
In SuperCollider così come in altri software a causa della compresenza di diversi linguaggi informatici alcune operazioni e istruzioni possono essere scritte in molti modi differenti. Le Routine tradizionali e l’abbreviazione sintattica (Syntax Shortcut) {}.fork(t) ne sono un esempio così come la possibilità di scrivere il codice in functional notation o receiver notation. A questo link possiamo trovarne un elenco esaustivo. Nell’usare questa abbreviazione sintattica dobbiamo però tenere conto di alcuni particolari e usare alcuni accorgimenti. Se ad esempio vogliamo usare il metodo .stop per interrompere la computazione è necessario invocare il metodo .fork() contestualmente all’assegnazione della funzione a una variabile, altrimenti non si fermerà in quanto SuperCollider interpreta tutto ciò che è incluso tra parentesi graffe come una funzione, non come una Routine. Se eseguiamo le righe da 1 a 11 del codice seguente, SuperCollider prima riporta la scritta a Routine e poi comincia a computare la sequenza. Se prima della fine eseguiamo la riga 12 si interrompe.
(
r = {"trigger_1".postln; 1.wait;
"trigger_2".postln; 1.wait;
"trigger_3".postln; 1.wait;
"trigger_4".postln; 1.wait;
"trigger_5".postln; 1.wait;
"trigger_6".postln;
}.fork
)
r.stop;
Se invece eseguiamo le righe da 1 a 11 del codice seguente SuperCollider restituisce a Function e non a Routine e se volessimo interrompere la sequenza dal codice dovremmo adottare altre strategie.
(
r = {"trigger_1".postln; 1.wait;
"trigger_2".postln; 1.wait;
"trigger_3".postln; 1.wait;
"trigger_4".postln; 1.wait;
"trigger_5".postln; 1.wait;
"trigger_6".postln;
}
)
r.fork; // parte ma...
r.stop; // non si stoppa,
La Routine parte eseguendo la riga 12 perchè il metodo .fork() quando invocato "trasforma" una funzione in una Routine, ma nel momento in cui invochiamo .stop sulla variabile r, SuperCollider la interpreta come funzione e non come Routine, non eseguendo ciò che gli stiamo chiedendo.
Task
Un Task all’apparenza è esattamente come una Routine. Accetta gli stessi metodi e segue la stessa sintassi. La principale differenza tra queste due Classi sta nel fatto che i primi possono essere messi in pausa e riprendere la computazione dal punto in cui li abbiamo fermati, mentre le Routine come abbiamo visto se stoppate possono solo essere resettate e ripartire dall’inizio.
(
r = Task({"trigger_1".postln; 1.wait;
"trigger_2".postln; 1.wait;
"trigger_3".postln; 1.wait;
"trigger_4".postln; 1.wait;
"trigger_5".postln; 1.wait;
"trigger_6".postln; 1.wait;
"trigger_7".postln; 1.wait;
"trigger_8".postln; 1.wait;
"trigger_9".postln;
})
)
r.play;
r.pause; // pausa
r.resume; // riprende
r.stop; // come pause
r.reset; // resetta all'inizio la prossima volta che viene eseguito
r.start; // riparte da capo
I metodi .play e .resume sono sinonimi così come .stop e .pause. I primi servono per far partire la computazione dal punto in cui si trova, i secondi per stopparla o metterla in pausa. Il metodo .start invece fa partire la computazione di un Task sempre dall’inizio, come se avessimo usato .reset.play().
Facciamo attenzione a non confondere la differenza tra Routine e Task appena esposta con la spiegazione data all’inizio del paragrafo sulle prime. Riassumendo le Routine possono solo essere eseguite da capo a fondo anche se interrotte prima del loro termine mentre i Task possono essere messi in pausa e riprendere dal punto in cui li abbiamo interrotti.
I Task sono dunque musicamente più funzionali delle Routine ma questa maggiore duttilità (come spesso avviene in informatica) ha un prezzo da pagare ovvero ci sono alcune limitazioni:
al loro interno le operazioni condizionali non funzionano bene,
non possiamo stoppare e riavviare velocemente un processo (a tempi inferiori dei tempi delta specificati al suo interno).
Per chi volesse approfondire queste e altre problemetiche riguardanti i Task può consultare il loro Help file dove troverà anche diversi esempi che illustrano queste limitazioni.
Clocks
Abbiamo visto come di default i valori temporali espressi nelle Routine e nei Task siano in secondi. In termini musicali musica però una sequenza di eventi può essere definita e misurata sia in Tempo assoluto (secondi e millisecondi) che in Tempo relativo (beat e sue suddivisioni). In SuperCollider possiamo adottare una o l'altra unità di misura specificando il tipo di Clock da utilizzare. Ne esistono tre, ognuno da utilizzare in una specifica situazione:
- SystemClock
- TempoClock
- AppClock
Possiamo pensare ai Clock come a metronomi che forniscono la griglia temporale all'interno della quale si svolgono gli eventi. I Clocks possono essere specificati come argomento dei metodi .play(Clock) e .fork(Clock) e vanno a modificare l'unità di misura degli eventi temporali presenti all'interno delle Routines sulle quali sono invocati:
(
d = SystemClock; // secondi
b = 120; // bpm
t = TempoClock(b/60); // bpm --> bps
a = AppClock; // secondi (per le GUI)
r = Routine({
0.5.wait; // sinonimo di .yield
"trig_1".postln;
2.wait;
"trig_2".postln;
0.1.wait;
"trig_3".postln;
});
)
r.reset.play(d); // Esegue la Routine a SystemClock (tempi in secondi 1 = 1 secondo)
r.reset.play(t); // Esegue la Routine a TempoClock (tempi in beats 1 = 1 beat metronomico)
r.reset.play(a); // Esegue la Routine a AppClock (tempi in secondi 1 = 1 secondo)
Vediamo i dettagli.
SystemClock
SystemClock è un oggetto di SuperCollider. Osserviamo nel dettaglio le sue caratteristiche richiamando il suo Help file. Gli Help files generalmente sono divisi in due o tre parti, una chiamata Description, un’altra Class Methods e la terza, quando presente Instance Methods.

Nella prima (Description è documentato lo stato dell’oggetto, ovvero a quale tipo di Data appartiene a quali messaggi può rispondere e quali sono le operazioni può compiere. Nella fattispecie dell’oggetto in trattazione:
- SystemClock è una subclasse della superclasse Clock che agisce in un thread separato rispetto a quello principale. E’ ad alta priorità (molto preciso) e accetta valori temporali espressi in secondi ovvero in tempo assoluto. Calma e gesso. Cerchiamo di chiarire. Pensiamo la superclasse Clock come se fosse un concetto-magazzino che racchiude in sè tutti i metronomi possibili (intesi come oggetto fisico e non come tempo metronomico) di tutte le marche passate, presenti e future. Immaginiamo poi che SystemClock (subclasse) sia una di queste marche. Infine pensiamo a un modello specifico di questa marca, con caratteristiche proprie (la forma, il suono del battito, il tipo di molle all’interno, etc.) che lo differenziano da tutti gli altri. Un musicista lo sceglie e lo accende. Lui comincia a scandire una sequenza di pulsazioni separate da tempi delta regolari. Questo flusso temporale può essere considerato un thread. Lo stesso musicista poi comincia a suonare un brano con il proprio strumento, seguendo le pulsazioni scandite dal metronomo. Possiamo pensare le azioni del musicista e il suo flusso temporale come un secondo thread (quello principale) che si sviluppa parallelo a quello del metronomo. Il nostro esecutore però può rallentare o accelerare più o meno coscientemente l’esecuzione, diventando a-sincrono rispetto ai battiti metronomici. In questo caso i due threads sono sempre paralleli ma indipendenti l’uno dall’altro. Se ad esempio l’esecutore viene sottposto a stress, come nel caso di dover eseguire molte note velocissime tra un beat e il successivo, si comporterà in modo differente rispetto al tempo parallelo del metronomo a seconda che segua un clock ad alta priorità o a bassa priorità. Nel primo caso terrà come obbiettivo principale il rimanere nel tempo scandito dal metronomo, magari non eseguendo tutte le note, ma presentandosi sempre puntuale sul battere del tempo, mentre nel secondo caso preferirà eseguire tutte le note tra i beat, rallentando automaticamente anche i tempi delta del metronomo.
Se vogliamo specificare il tempo in secondi possiamo evitare di definire un Clock in quanto SystemClock è il Clock di default ed è anche il più preciso, se invece vogliamo gestire il tempo musicale in tempo relativo dobbiamo specificarne un altro: TempoClock.
TempoClock
Anche TempoClock è uno scheduler ma rispetto a SystemClock presenta alcune differenze sostanziali che lo rendono musicalmente più versatile ma tecnicamente meno preciso. Osserviamo nel dettaglio quali sono le sue caratteristiche:
- Misura il tempo in bps (beat per second) invece che in secondi e non opera in un thread separato. Questo ci permette di pensare
a nostro piacimento sia in tempo relativo che in tempo assoluto:
1 bps = 1 pulsazione = 60 di metronomo (bpm) = 1 secondo = 1000 ms
- Possiamo stabilire il tempo delta che intercorre tra i beats, specificandolo come argomento (in bps).
SystemClock; // beat = 1 secondo TempoClock; // beat = 1 bps (default) TempoClock(2); // beat = 2 bps (indicato come argomento)
Se non specifichiamo alcun argomento (come nella riga 2 del codice precedente), TempoClock adotta 1 bps come valore di default. I valori di default sono quelli che la maggior parte degli oggetti di SuperCollider assumono all’apertura del patch se non ricevono altre indicazioni al riguardo. Possiamo verificarli negli Help files di quasi tutti gli oggetti. A differenza dei valori di default che assegnamo agli argomenti delle funzioni questi rimangono invariati fino a quando nel corso della computazione non vengono modificati (sovrascritti) come se fossero delle variabili. In questo caso il nuovo valore sostituisce definitivamente quello di default, che ritornerà solamente alla successiva riapertura del patch. TempoClock accetta come unità di misura i bps ma in genere i musicisti preferiscono scandire il beat in bpm o tempo metronomico. Possiamo allora specificare come argomento di TempoClock non il singolo valore numerico in bps ma l’operazione aritmetica che converte i bpm in bps:TempoClock(72/60); // bps = bpm/60
A questo punto tutti i valori temporali scritti nelle righe di codice soggette allo specifico TempoClock, sono in relazione a quel beat inteso come unità (1.0 = 1 beat) ovvero in tempo relativo. Se manteniamo ad esempio la pulsazione di default (1 bps) e assegnamo il beat a una semiminima (quarto) come illustrato nella Figura seguente:
otteniamo i seguenti valori relativi e assoluti:
1 = 1000 ms = 1 quarto = 1/1 = 1.0 bps 0.5 = 500 ms = 1 ottavo = 1/2 = 2.0 bps 0.333 = 333 ms = 1 ottavo terzinato = 1/3 = 3.0 bps 0.25 = 250 ms = 1 sedicesimo = 1/4 = 4.0 bps 0.666 = 666 ms = 1 quarto di terzina = 2/3 = 1.5 bps 0.125 = 125 ms = 1 trentaduesimo = 1/8 = 8.0 bps 1.5 = 1500 ms = 1 quarto puntato = 3/2 = 0.6 bps 2 = 2000 ms = 1 metà = 2/1 = 0.5 bps etc.
Facciamo attenzione a non confondere le suddivisioni del tempo in bps con quelle riferite all’unità del beat. Le prime si usano solo come argomento di TempoClock, le seconde all’interno del codice soggetto a un TempoClock per indicare tempi delta, durate e onsets. Ad esempio se il beat (1.0) è uguale a 1 bps, 2 bps corrispondono a 0.5 beat.
Se cambiamo il valore del beat da 60 a 92 bpm (TempoClock(92/60)) tutti i valori calcolati in tempo assoluto vengono riscalati e ricalcolati automaticamente da SuperCollider mantenendo invariati i rapporti relativi.1 = 652 ms = 1 quarto = 1/1 0.5 = 326 ms = 1 ottavo = 1/2 0.333 = 217 ms = 1 ottavo terzinato = 1/3 0.25 = 163 ms = 1 sedicesimo = 1/4 0.666 = 434 ms = 1 quarto di terzina = 2/3 0.125 = 81 ms = 1 trentaduesimo = 1/8 1.5 = 978 ms = 1 quarto puntato = 3/2 2 = 1304 ms = 1 metà = 2/1 etc.
Da questo si evince la comodità di esprimere i valori temporali come fattori di moltiplicazione di un beat. Se avessimo lavorato in tempo assoluto, per ogni cambio di metronomo (più lento o più veloce) avremmo dovuto ricalcolare e riscrivere a mano tutti i valori nel codice, mentre così ne riscriviamo uno solo (l’argomento di TempoClock). nfine se per qualche motivo invece volessimo lavorare in un tempo assoluto utilizzando TempoClock basterà specificare i seguenti valori in bps come argomento:- 1 nel caso volessimo specificare nel codice valori temporali in secondi.
- 1000 nel caso li volessimo specificarli in millisecondi.
Nell’esempio seguemte sono presenti le tre unità di misura temporale che possono essere specificate in TempoClock, da scegliere accuratamente in base alle specifiche esigenze musicali o tecniche.
TempoClock.new(92/60); // Valori espressi in fattori di moltiplicazione del beat (1.0) e convertiti automaticamente da SC TempoClock.new(1); // Valori espressi in secondi (1 bps) TempoClock.new(1000); // Valori espressi in millisecondi (1000 bps)
- Possiamo creare più istanze di TempoClock all’interno dello stesso codice, sia riferendosi a un pensiero musicale
orizzontale, come la presenza di cambi metronomici nel corso di un brano, (nel codice seguente le righe da 2 a 5) che
verticale come in un brano poli-metrico (nel codice seguente il blocco tra le righe 6 e 9). Per farlo dobbiamo invocare il
metodo .new():
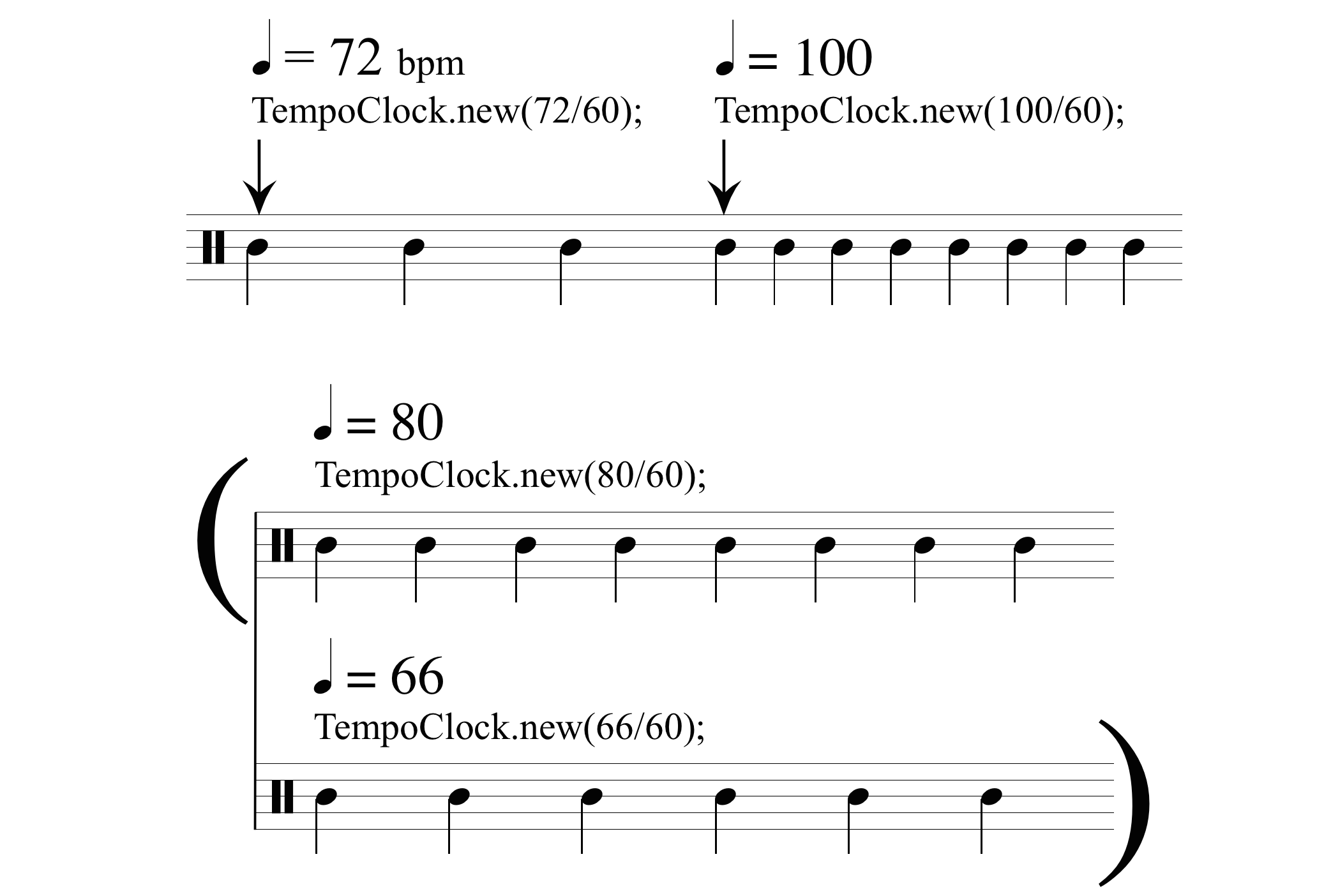
SystemClock; // E'una Classe TempoClock.new(72/60); // E'un'Istanza // in queste righe bpm = 72 // ... TempoClock.new(100/60); // da qua cambia...(bpm = 100) // ma e' una nuova istanza ( TempoClock.new(80/60); // Polimetrico TempoClock.new(66/60); // (sincronizzato) )In generale per creare una nuova istanza da una Classe dobbiamo invocare il metodo .new che può anche essere sottointeso:TempoClock.new(100/60); TempoClock(100/60); // .new e' sottointeso
- Possiamo cambiare dinamicamente nel corso della computazione il valore del beat di ogni singola istanza di TempoClock.
Negli esempi precedenti ad ogni esecuzione del codice abbiamo creato nuove istanze di TempoClock, anche a ogni cambio di tempo, il
che nella vita reale corrisponde al materializzare un nuovo metronomo (sempre inteso come oggetto) a ogni variazione di bpm. Così come
nella vita reale può non essere la soluzione più pratica ed economica a meno che non ci si occupi di magia, anche in quella virtuale nella
maggior parte dei casi non è la strategia migliore da adottare. Possiamo cambiare il valore del tempo delta di ogni singola istanza di
TempoClock (bps) in questo modo:
- la assegnamo a una variabile
- e inviamo un messaggio che invoca il metodo .tempo e che adotta la seguente sintassi: .tempo = nuovo_bps.
a = TempoClock.new(100/60); // assegna un istanza di TempoClock alla variabile 'a' e specifica un tempo a 100 bpm a.tempo = 82/60; // se eseguiamo questa riga bpm = 82 a.tempo = 66/60; // se eseguiamo questa riga bpm = 66
Quando incontriamo la sintassi Classe.metodo = valore come in questo caso, possiamo usare anche un’altra scrittura: Classe.metodo_(valore). Non c’è differenza sostanziale tra le due, a volte è preferibile usarne una, altre l’altra.a = TempoClock.new(100/60); a.tempo = 82/60; a.tempo_(66/60);
Risulta evidente dalla Figura precedente illustrante l'Help file di TempoClock che .tempo è un metodo d’istanza mentre fino a questo punto avevamo incontrato solo metodi di classe. Qual’è la differenza tra i due? Per quanto riguarda i primi (metodi di classe), semplicemente possono essere invocati da una Classe (come .sched per SystemClock), mentre per i secondi (metodi d’istanza) prima di invocarli dobbiamo creare una nuova istanza con il metodo .new ed eventualmente assegnarla a una variabile (locale o globale a seconda dei casi) alla quale indirizzare il messaggio.
Possiamo modificare il tempo di default di TempoClock, ovvero quello adottato da SuperCollider quando lo lanciamo senza specificare nulla. Per farlo dobbiamo invocare prima il metodo .default e poi .tempo = bps.
TempoClock.default.tempo = 2; TempoClock.default.tempo = 92/60; TempoClock.default.tempo_(100/60);
Se nel codice però specifichiamo un TempoClock questo sostituisce quello di default, che sarà utilizzato solo se usciamo e rilanciamo l’applicazione.Possiamo monitorare il tempo trascorso anche in TempoClock recuperando diverse informazioni. Così come per SystemClock per farlo dobbiamo invocare il metodo .schedAbs(). Eseguiamo il codice seguente e leggiamo nella post window quali informazioni sono stampate.
( t = TempoClock; t.schedAbs(0, {arg ora; ora.postln; 0.5}) )TempoClock a differenza di SystemClock in questo caso riporta il tempo (onset) trascorso da quando è stata creata l’istanza e non da quando è stata lanciata l’applicazione. Se però sostituiamo il singolo argomento 'ora' (che è una parola scelta da noi) con la keyword ...args (che è una parola riservata, ovvero deve essere scritta proprio così) otteniamo anche altre informazioni.( t = TempoClock; t.schedAbs(0, {arg ...args; args.postln; 0.5}) )Nel dettaglio viene riportato a intervalli regolari un array che contiene tre items:[ 823, 1826.721775765, a TempoClock ]
che corrispondono a:- tempo trascorso dalla creazione dell’istanza,
- tempo trascorso dal lancio di SuperCollider,
- tipo di Classe che riporta queste informazioni.
Anche in questo caso come per SystemClock possiamo recuperare solo l’informazione sul tempo parziale, ovvero il tempo trascorso dalla creazione dell’istanza di TempoClock in beats invocando il metodo .elapsedBeats.
t = TempoClock(1); // eseguire prima questa riga t.elapsedBeats; // quanti beats sono trascorsi?
Come possiamo verificare nella post window i valori sono float con molti decimali. Se volessimo solo il numero di beat senza decimali (int) dovremmo approssimare i valori all’unità, o meglio effettuare una quantizzazione metrica, in quanto l’esecuzione "manuale" della riga t.elapsedBeats; potrebbe non cadere esattamente "sul tempo" ma tra un beat e l’altro. Per casi come questo possiamo utilizzare due metodi che ci permettono di precisare se vogliamo il valore del beat precedente (.floor) o di quello seguente (.ceil).// N.B. 1 beat ogni 5 secondi... t = TempoClock(0.2); // eseguire prima questa riga t.elapsedBeats.ceil; // il prossimo beat t.elapsedBeats.floor; // il beat precedente
AppClock
Ai fini pratici AppClock. è uno scheduler del tutto simile a SystemClock in quanto:
- misura il tempo in secondi.
- possono essere invocati gli stessi metodi.
- svolge le stesse funzioni.
Ci sono però due differenze. La prima è tecnica e consiste nel fatto che vive nello stesso thread dell’applicazione mentre SystemClock in uno separato. La seconda è più pratica: SystemClock è uno scheduler ad alta priorità mentre AppClock a bassa priorità e questa è la discriminante maggiore nel decidere di utilizzare uno o l’altro. Infatti ogni volta che vorremo visualizzare parametri dinamici (che cambiano nel tempo) su una GUI (Graphic User Interface) dovremo obbligatoriamente utilizzare AppClock che essendo a bassa priorità darà la preferenza alla computazione dell’audio e solo se il computer avrà ancora risorse disponibili computerà anche la parte visiva.
Sequencing
Da questo Paragrafo in poi per facilitare la comprensione degli esempi a livello percettivo useremo un sintetizzatore sinusoidale percussivo.
Sintetizzatore percussivo
// frequenze in Hz
// ampiezze tra 0.0 e 1.0
// durate in secondi
(
s = Server.local.boot;
SynthDef(\sperc, {|freq =440, amp=0.5, dur=0.5, atk=10, gate=1.0|
var durms = dur*1000,
env = EnvGen.ar(Env.perc(0.01, dur-0.01),gate,doneAction: 2),
osc = SinOsc.ar(freq, 0, amp);
Out.ar(0, env *osc ! 2)
}).add;
)
Dopo aver compiuto questa operazione torniamo agli esempi di codice illustrati nei paragrafi precedenti dove abbiamo definito sequenze di eventi nel tempo. Una delle azioni che abbiamo chiesto di compiere a SuperCollider è stata quella di stampare qualcosa nella post window all’onset di ogni evento.
(
b = 120;
t = TempoClock(b/60);
r = Routine({"trigger".postln; // stampa
0.5.yield; // aspetta
"trigger".postln;
0.5.yield;
"trigger".postln;
}).reset.play(t);
)
Ora che abbiamo a disposizione un Synth possiamo aggiungere una seconda azione: fargli suonare una nota. Anche in questo caso possiamo utilizzare la sintassi usata nelle righe 5, 8 e 11 del prossimo riquadro così come è, senza entrare nel merito, ci basti sapere che contiene le istruzioni necessarie per eseguire una singola nota con una altezza una durata e un’intensità predefinite (valori di default) da inviare al Synth definito in precedenza.
(
b = 120;
t = TempoClock(b/60);
r = Routine({"trigger".postln; // stampa
Synth("sperc"); // suona
0.5.wait; // aspetta
"trigger".postln;
Synth("sperc");
0.5.wait;
"trigger".postln;
Synth("sperc");
}).reset.play(t)
)
Se non abbiamo la necessità di monitorare visivamente il trigger degli eventi o altre informazioni riguardanti la computazione, possiamo omettere le righe dove chiediamo a SuperCollider di stampare qualcosa nella post window.
(
b = 120;
t = TempoClock(b/60);
r = Routine({Synth("sperc"); // suona
0.5.wait; // aspetta
Synth("sperc");
0.5.wait;
Synth("sperc");
}).reset.play(t);
)
Usando la sintassi Synth("sperc") in questo punto del codice abbiamo uno strumento polifonico che virtualmente crea e distrugge un Synth a ogni nota, utilizzando una tecnica chiamata dynamic voice allocation che permette di ridurre notevolmente il consumo di cpu del computer. Non essendo però questa tematica propria della sezione corrente, per ora pensiamolo semplicemente come un pianoforte virtuale.
Loop con n.do({})
Nei Paragrafi precedenti dedicati alla programmazione di SuperCollider abbiamo visto come programmare sequenze di eventi specificando esclusivamente un solo valore per i tempi delta oppure scrivendo un solo evento per riga:
(
Routine.new({Synth("sperc");
1.00.wait;
Synth("sperc");
0.75.wait;
Synth("sperc");
0.25.wait;
Synth("sperc");
0.33.wait;
Synth("sperc");
0.33.wait;
Synth("sperc");
0.33.wait;
Synth("sperc");
0.5.wait;
Synth("sperc");
0.5.wait;
}).play;
)
Utilizzando questa sintassi abbiamo però il problema che per scrivere brani di una certa durata andiamo a generare patch della lunghezza pari a quella dei poemi epici. Fortunatamente per ovviare a questo inconveniente ci sono degli oggetti che generano dei loop nel codice e che possono essere usati anche all’interno di una Routine. Il più importante per quello che riguarda questo Paragrafo segue la sintassi n.do({}).
Partiamo con la più semplice delle sequenze di eventi nel tempo: la successione di pulsazioni regolari. Possiamo definire questo tipo di sequenza con il ripetersi di due azioni che si susseguono uguali per un numero finito o infinito di volte nel tempo (in questo caso la durata dell’evento è sottintesa e coincide con il tempo delta).
(
b = 92;
t = TempoClock(b/60); // beat
r = Routine({
//------------------------------------------- 1 ripetizione
Synth("sperc"); // onset evento
1.wait; // tempo delta di attesa
//------------------------------------------- 2 ripetizione
Synth("sperc");
1.wait;
//------------------------------------------- 3 ripetizione
Synth("sperc");
1.wait;
//------------------------------------------- etc.
}).reset.play(t);
)
La sintassi n.do({}) permette di abbreviare il codice per operazioni di questo tipo (iterazioni), ed è traducibile in: ripeti n volte la valutazione delle righe contenute nella funzione specificata come argomento. Quando hai finito eventualmente prosegui oltre. Possiamo anche pensare questo tipo di loop come al corrispondente informatico di un ritornello musicale.
(
b = 92;
t = TempoClock(b/60);
r = Routine({
3.do( // ripeti 3 volte
//------------------------------------------- (ritornello)
{Synth("sperc");
1.wait;}
//-------------------------------------------
) // fine loop
}).reset.play(t); // fine Routine
)
Dovrebbe ora risultare chiaro il perchè in alcuni paragrafi precedenti per scopi puramente esemplificativi abbiamo sostenuto l’assunto: 1 riga di codice = 1 evento specificando al contempo che questa non è un’affermazione sempre valida. Allontanandoci ora dalle specifiche esigenze di temporizzazione degli eventi musicali vediamo come questo oggetto possa essere utilizzato anche al di fuori delle Routine, in qualsiasi punto del codice. In questi casi l’esecuzione del loop avverrà a velocità massima di scheduling:
10.do({"ciao".postln}) // valuta 10 volte il contenuto della funzione
Eseguendo la riga precedente vedremo stampata dieci volte la parola "ciao" nella post window ad altissima velocità (una parola per riga), seguita dal numero 10 che riporta quante volte la funzione è stata valutata (anche se in questo caso lo abbiamo specificato noi). L’esempio seguente invece illustra come le due situazioni (loop temporizzato all’interno di una Routine o a tempo di scheduling) possano convivere all’interno dello stesso patch e quali caratteristiche musicali differenti possono assumere. Ricordiamo che la computazione del codice di SuperCollider avviene in quasi tutti i casi dall'alto verso il basso e, una volta terminato un loop prosegue alla riga successiva.
(
b = 92;
t = TempoClock(b/60);
r = Routine({
3.do({ // ripeti questo 3 volte
Synth("sperc");
1.wait;
});
4.do({ // poi ripeti questo 4 volte
0.5.wait;
5.do({Synth("sperc",[\freq,rrand(90,100)]);
0.25.wait // questo loop
});
0.125.wait
});
2.wait; // aspetta 2 beats
5.do({Synth("sperc",[\freq,rrand(20,110)])}) // accordo di 5 note...
}).reset.play(t); // fine Routine
)
r.stop;t.clear; // per stop prima del tempo

Notazione musicale con ritornelli (le altezze cambiano in modo pseudo-casuale a ogni esecuzione)

Notazione musicale estesa (le altezze cambiano in modo pseudo-casuale a ogni esecuzione)
La sintassi n.do({}) genera sequenze finite, che hanno una lunghezza pari al numero di ripetizioni che specifichiamo. Se vogliamo invece generare sequenze infinite possiamo semplicemente sostituire il numero di ripetizioni con la parola riservata (keyword) inf. In questo caso il loop va avanti all’infinito fino a quando non stoppiamo la computazione in uno dei modi che conosciamo.
(
b = 120;
t = TempoClock(b/60);
r = Routine({ inf.do({Synth("sperc"); 0.5.yield}) }).reset.play(t);
)
r.stop; // stoppa la Routine
r.reset.play(t); // rewind, play
t.clear; // distrugge l'istanza di TempoClock
In tutti i casi in cui l’unico argomento di un oggetto è una funzione (come nel caso di Routine({}), Task({}) e n.do({})), le parentesi tonde possono essere omesse.
5.do{"ciao".postln};
Routine{Synth("sperc"); 0.5.wait; Synth("sperc")}.play;
(
b = 120;
t = TempoClock(b/60);
r = Routine{ 6.do{Synth("sperc"); 0.5.yield} }.reset.play(t);
)
Tuttavia fino a quando non saremo più familiari con il linguaggio di SuperCollider è preferibile utilizzare la sintassi tradizionale. Un altro oggetto che possiamo usare per iterare all’infinito una funzione è loop{} (oppure {}.loop).
(
b = 120;
t = TempoClock(b/60);
r = Routine({
loop{Synth("sperc"); 0.5.yield}
});
r.reset.play(t);
)
r.stop;
// Altra scrittura...
(
b = 120;
t = TempoClock(b/60);
r = Routine({
{Synth("sperc"); 0.5.yield}.loop
});
r.reset.play(t);
)
r.stop;
Quando generiamo loop infiniti con una qualsiasi delle sintassi appena illustrate, dobbiamo obbligatoriamente specificare un tempo delta con i metodi .wait o .yield in quanto se omettiamo queste "pause" tra valutazioni successive della funzione, SuperCollider le esegue il più veloce possibile e all’infinito, andando in crash.
Tutto ciò che è stato appena esposto funziona nella realizzazione di sequenze di eventi che seguono pulsazioni regolari, ma se volessimo generare sequenze con ritmi diversi senza scrivere 1 evento per riga di codice dovremmo utilizzare delle collezioni di tempi delta differenti rappresentate sotto forma di liste o Array.
Array
Un Array è una sequenza di valori che può essere indicizzata con numeri interi, come in un piano cartesiano (xy). I tempi delta che descrivono una sequenza ritmica sono valori e possono dunque essere indicizzati:

In questo caso si parla di sequenza numerica bidimensionale (2D).
Valori = y = 1.00, 0.75, 0.25, 0.33, 0.33, 0.33, 0.50, 0.50 Indici = x = 0 , 1 , 2 , 3 , 4 , 5 , 6 , 7
Questo tipo di sequenze in SuperCollider sono ottimizzate in una superClasse di oggetti chiamata SequenceableCollection. Gli indici x sono sottintesi e partono sempre da 0 mentre i valori o gli oggetti che compongono la collezione (chiamati items) sono inclusi tra parentesi quadre e separati tra loro da una virgola. La super-Classe SequenceableCollection contiene numerose Classi. Le due più utilizzate sono:
- Array. Possono contenere ogni tipo di oggetto e hanno una lunghezza definita.
- List. Uguali agli Array, ma è possibile variarne dinamicamente la lunghezza.
Qalsiasi tipo di data può essere collezionato in un Array o in una List (int, float, Synth, Envelope, midi, etc.) così come illustrato nel riquadro seguente:
[60,63,78,98,12] // sequenza di midi note [0.5,0.25,0.25,1] // sequenza di tempi delta [12,67,89,127,45] // sequenza di velocity [440,569,890,987] // insieme di frequenze [0.2,0.4,0.8,0.2] // insieme di ampiezze [SinOsc.ar(440),SinOsc.ar(441)] // insieme di segnali [rand(10),rand(0.1),rand(1000)] // insieme di funzioni
Attenzione, in realtà le prime cinque righe contengono solo numeri int e float compresi in ambiti che possono essere mappati su parametri corrispondenti alle unità di misura indicate (midi note, tempi delta, etc.).
Se includiamo una collezione di oggetti tra due parentesi quadre SuperColllider la interpreta automaticamente come un Array, mentre se vogliamo la interpreti come List dobbiamo specificarlo utilizzando una sintassi che apprenderemo più avanti. Sugli elementi che sono all’interno di un Array (items) possiamo effettuare numerose operazioni, manipolazioni, sostituzioni di posizione, di data, e altre diavolerie, ma per gli scopi di questo Paragrafo ci interessa solo un particolare tipo di Array chiamato Literal array. La sua caratteristica è che non può essere modificato e che come tipo di data fa parte dei Literals già illustrati in precedenza. E’ caratterizzato dal simbolo # prima della parentesi di apertura.
#[1,0.75,0.25,0.33,0.33,0.33, 0.5,0.5];
L’aver illustrato le caratteristiche principali di List, Array e Literal Array ci permette di osservare una problematica tipica dei software musicali (e non solo) ovvero il dover spesso scegiere tra più oggetti che apparentemente hanno le stesse funzioni (come in questo caso collezionare e indicizzare data). Solitamente dobbiamo effettuare questa scelta tenendo conto dell’assunto: versatilità vs costo computazionale o meglio scegliere in base alle nostre esigenze di programmazione quello che ha un minor costo computazionale. Prendiamo ad esempio le tre Classi di cui sopra.
Literal Array - Prima scelta. Se sappiamo che il contenuto non sarà modificato nel corso della computazione sceglieremo questo oggetto in quanto meno versatile ma più "leggero".
Array - Seconda scelta. Se vogliamo effettuare operazioni sul contenuto della collezione ma non sulla sua lunghezza utilizzaremo questo oggetto.
List - Terza scelta. Se vogliamo effettuare operazioni e anche modificare il numero di items in esso contenuti sceglieremo questo oggetto in quanto più versatile ma più "pesante".
Per collezioni di valori numerici la differenza di costo computazionale è solitamente irrisoria ma per collezioni di segnali audio, inviluppi o altri tipi di data può essere rilevante e dunque da tenere in considerazione.
Visualizzazione
Quando un Array contiene valori numerici, possiamo visualizzarli graficamente su un piano cartesiano utilizzando gli indici (sottintesi) come ascisse (x) e i valori (items) come ordinate (y). Per farlo abbiamo a disposizione due possibili sintassi: la prima utilizza il metodo .plot() invocato direttamente sull'Array mentre la seconda la Classe Plotter.
Plotting
Se vogliamo generare una visualizzazione grafica (Plotter) dei dati contenuti in un Array a ogni valutazione, possiamo farlo invocando su di esso il metodo .plot(). Apparirà una nuova finestra come quella illustrata nella Figura seguente e la scritta a Plotter sarà stampata nella Post window.
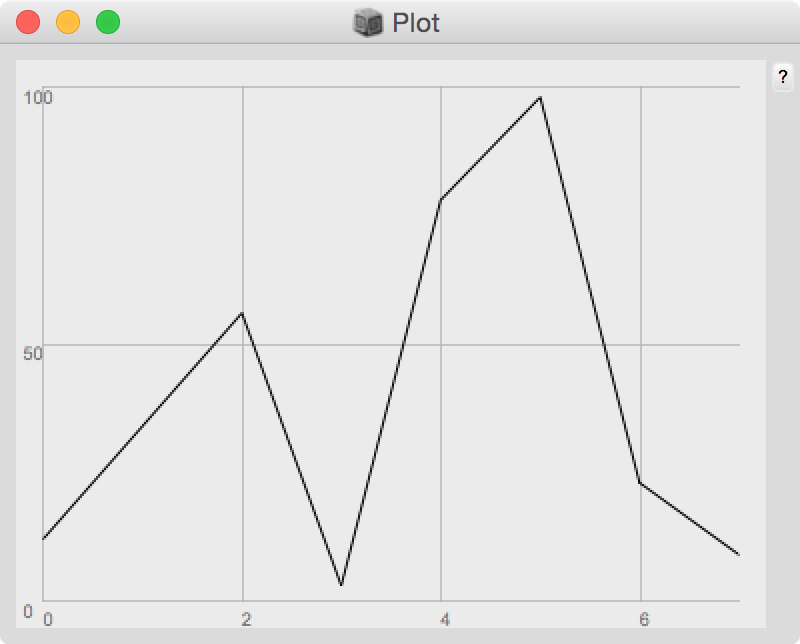
#[12,34,56,3,78,98,23,9].plot; // valori determinati Array.rand(100, -1.0,2.5).plot; // valori pseudo-casuali tra -1 e 2.5
Questo metodo come molti altri può essere invocato su diversi tipi di oggetti (polimorfismo) , tra i quali gli Array. Per sapere quali sono dobbiamo selezioniarlo e schiacciare cmd+d, come quando richiamiamo un Help file. Se però eseguiamo questa operazione sui metodi, nell’Help browser non compare un Help file ma un elenco di oggetti sui quali possono appunto essere invocati.

L’aspetto grafico di un Plotter è personalizzabile attraverso gli argomenti di .plot(). Facciamo attenzione che a seconda del tipo di data sul quale è invocato, gli argomenti di questo metodo cambiano. Nell’esempio seguente sono presenti quelli spendibili nella visualizzazione di Array numerici.

(
a = #[12,34,56,3,78,98,23,9];
a.plot(name: "mio plot", // nome
bounds:540@200, // dimensioni x@y in pixels
minval: -100, // valore limite inferiore
maxval: 100, // valore limite superiore
discrete:true) // true = punti, false = linee
)
Fra questi è sempre raccomandabile specificare minval e maxval perchè di default i limiti si "adattano" ai valori contenuti nell’Array e questo potrebbe generare errori di lettura e valutazione. Nell’esempio seguente la visualizzazione dei valori può trarre in inganno (nell’Array in alto sono compresi tra 0.1 e 1.0 mentre in quello in basso tra 1 e 10).
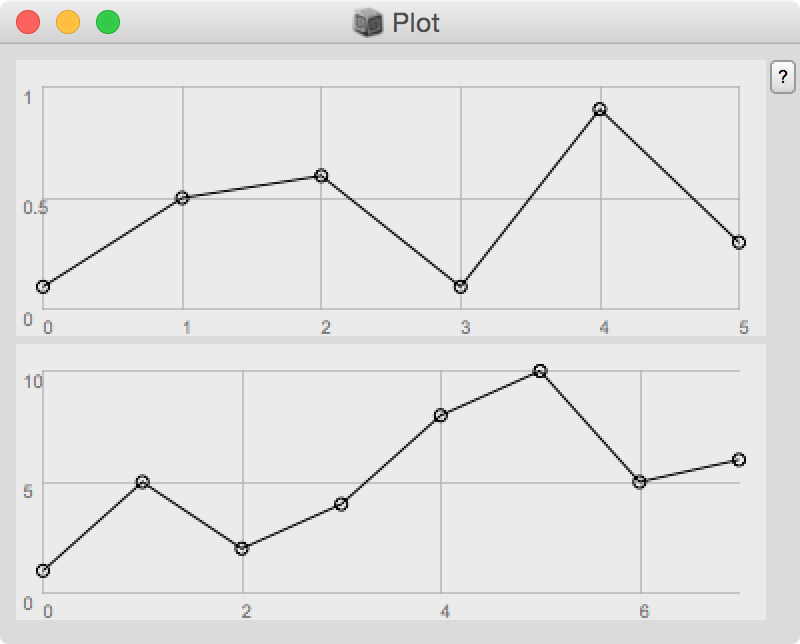
( [#[0.1,0.5,0.6,0.1,0.9,0.3], #[1,5,2,4,8,10,5,6]].plot; )
Specificando i limiti invece la visualizzazione sarà decisamente più corrispondente alla realtà e più leggibile:
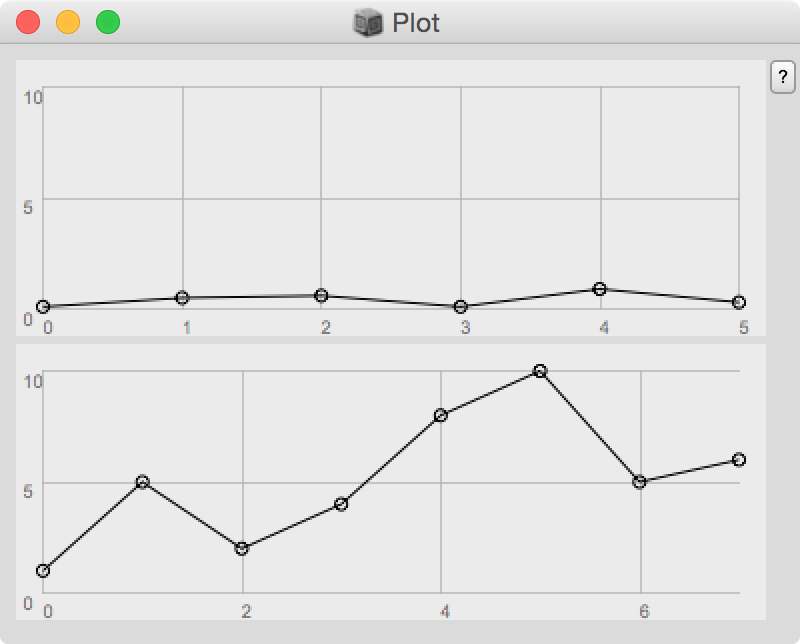
( [#[0.1,0.5,0.6,0.1,0.9,0.3], #[1,5,2,4,8,10,5,6]]..plot(minval:0,maxval:10); )
Plotter
Se invece vogliamo creare una sola finestra, all’interno della quale visualizzare e cancellare a ogni esecuzione diversi valori possiamo utilizzare direttamente la Classe Plotter.
Plotter.new;
a = Plotter.new("segmenti",300@200);
a.value = #[23,12,45,32,65];
a.value_(#[1,2,3]);
a.value = #[10,2,33,41,50,23,45,56];
Per farlo dobbiamo compiere due distinte operazioni.
creare una finestra vuota o meglio un’istanza della Classe Plotter (riga 1 e 2 del codice precedente):

Ricordiamo che il metodo .new può essere sottinteso. Gli argomenti sono gli stessi che abbiamo visto per il metodo .plot().
riempire la finestra specificando i valori y con il metodo che già conosciamo .value = [items] (riga 3 del codice precedente):
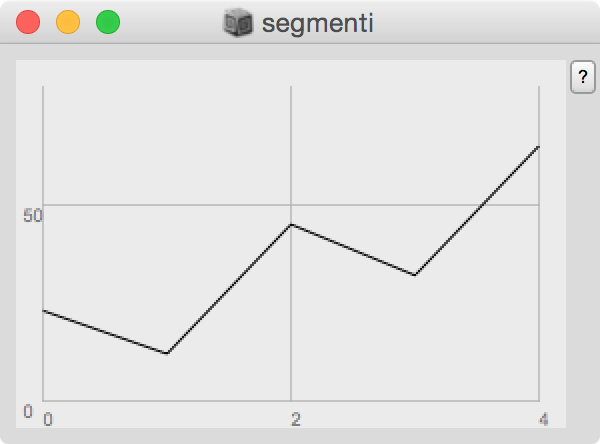
Questa seconda operazione possiamo effettuarla quante volte vogliamo. Il numero di items può variare a piacere e i limiti della finestra si adattano automaticamente ai nuovi valori. Notiamo la differenza rispetto all’utilizzo di questo metodo quando è assegnato a una funzione:
// Funzioni a = {arg a,b; a+b}; a.value(3,6); // Plotter a = Plotter("segmenti",300@200); a.value = #[23,12,45,32,65]; a.value_( #[1,2,3] );Come abbiamo già visto nel Paragrafo dedicato a TempoClock le sintassi usate nelle ultime due righe si equivalgono e possiamo utilizzarne una o l’altra a nostro piacimento.
I due modi appena esposti di visualizzare i valori di un Array si equivalgono in quanto entrambi generano un’istanza della Classe Plotter. Il primo chiede a SuperCollider di farlo per noi attraverso il metodo .plot(). Il secondo ci permette di farlo noi direttamente sottointendendo il metodo .new.
Una volta generata una finestra grafica contenente un Plotter possiamo modificare il suo aspetto grafico anche con il metodo .setProperties():
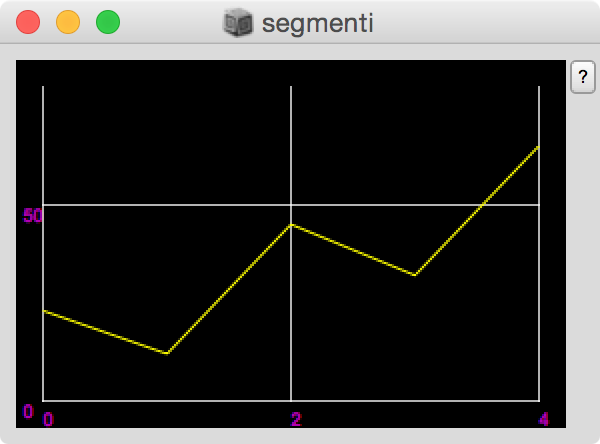
(
a = Plotter("segmenti",300@200);
a.value = #[23,12,45,32,65];
a.setProperties(
\backgroundColor, Color.black, // sfondo
\plotColor, Color.yellow, // data
\fontColor, Color.magenta, // numeri
\gridColorX, Color.white, // griglia x
\gridColorY, Color.white, // griglia Y
);
)
Una lista esaustiva di tutte le proprietà grafiche che possiamo modificare la troviamo richiamando l’Help file di questo metodo. Infine possiamo interagire con un Plotter attraverso alcune abbreviazioni da tastiera. Selezioniamo la finestra con un click.
per cambiare il tipo di visualizzazione (.plotMode()): premere il tasto m più volte. Ci sono 5 diverse modalità di visualizzazione: \linear, \points, \plines, \levels, \steps.
per utilizzare uno Zoom verticale: premere i tasti +/-
per editare i punti (valori y) con il mouse (Editing mode switch): premere il tasto e. Le modifiche avvengono solo sul Plotter, l’Array originale non viene modificato.
per visualizzare o meno una griglia orizzontale: tasto g
per visualizzare o meno una griglia verticale: tasto G
per stampare nella Post window una coppia di valori (xy): schiacciare alt e cliccare sul punto desiderato.
Lettura in sequenza
Qualsiasi tipo di sequenza ritmica (e non solo) può essere rappresentata con un Array. Questi però soto un punto di vista informatico sono collezioni di data e non hanno nulla a che fare con il tempo. Leggere un Array che descrive una sequenza di valori musicali è come leggere una partitura tradizionale senza suonarla. Il parametro temporale entra in gioco solo nel momento dell’esecuzione, nota dopo nota. Anche per gli Array dobbiamo dunque avere la possibilità di richiamare a nostro piacere nel tempo ogni singolo item. Possiamo farlo grazie al fatto che sono collezioni indicizzate (id, item) e ottenere di volta in volta ogni singolo elemento (item) richiamandone l’indice sottinteso (id) attraverso diversi metodi.
[].at()
Il primo e il più utilizzato è [].at().
a = #[1, 0.75, 0.25, 0.33, 0.33, 0.33, 0.5, 0.5]; // items // 0 1 2 3 4 5 6 7 // indici sottointesi a.at(0); // 1 a.at(1); // 0.75 a.at(2); // 0.25 a.at(3); // 0.33 etc....
Osserviamo come sia uso comune assegnare un Array a una variabile per poi richiamare i singoli items specificandone l’indice sottointeso come argomento del metodo [].at() in valutazioni successive. Il primo indice è sempre 0. Possiamo anche utilizzare un’abbreviazione sintattica che corrisponde alla notazione adottata nel linguaggio Java, anche se personalmente (tranne che in alcuni casi particolari) preferisco la notazione tradizionale.
a = #[1, 0.75, 0.25, 0.33, 0.33, 0.33, 0.5, 0.5]; // items // 0 1 2 3 4 5 6 7 // indici a[0]; // 1 a[1]; // 0.75 a[2]; // 0.25 a[3]; // 0.33 etc....
Un’informazione che come vedremo può tornare utile in numerose occasioni è conoscere il numero di items contenuti in un Array e la possiamo ottenere invocando il metodo .size.
a = #[1, 0.75, 0.25, 0.33, 0.33, 0.33, 0.5, 0.5]; a.size; // --> 8
Se in assenza di quest’ultima informazione e per qualsiasi motivo dovesse essere richiamato un indice maggiore della lunghezza dell’Array (size-1 in quanto il primo indice è 0) o minore di 0, SuperCollider riporta nil come dimostrato nell’esempio seguente.
(
var a = #[1, 0.75, 0.25, 0.33, 0.33, 0.33, 0.5, 0.5], // items
// 0 1 2 3 4 5 6 7 // indici
id = rrand(-5,10), // valori tra -5 e 10
item = a.at(id); // richiama
[id, item] // stampa
)
Per ovviare a quanto appena esposto in questo caso possiamo utilizzare o il metodo [].size come argomento di rand(),
(
var a = #[1, 0.75, 0.25, 0.33, 0.33, 0.33, 0.5, 0.5],
id = rand(a.size), // valori tra 0 e 7 (size-1)
item = a.at(id);
[id, item]
)
oppure altri tre metodi che sono parenti stretti di [].at().
[].clipAt()
Se per qualsiasi motivo il numero che richiama gli indici è superiore al size o inferiore a 0, riporta l’ultimo item sia oltre il size che per numeri negativi:
(
var a = #[1, 0.75, 0.25, 0.33, 0.33, 0.33, 0.5, 0.5], // items
// 0 1 2 3 4 5 6 7 // indici
id = rrand(-5,10),
item = a.clipAt(id);
[id, item]
)
[].wrapAt()
Se per qualsiasi motivo il numero che richiama gli indici è superiore al size torna all’indice 0 e continua a contare. Come in un loop. Nell’esempio seguente se rand(15) genera 10 riporta l’elemento che è all’indice 2 (10 - 8 che è il size), se invece esce 14 quello a indice 6 (14 - 8)e così via. Funziona anche con indici negativi.
(
var a = #[1, 0.75, 0.25, 0.33, 0.33, 0.33, 0.5, 0.5], // items
// 0 1 2 3 4 5 6 7 // indici
id = rand(15),
item = a.wrapAt(id);
[id, item]
)
[].foldAt()
Se per qualsiasi motivo il numero che richiama gli indici è superiore al size o inferiore a 0 continua la conta in modo speculare. Nell’esempio seguente se esce 13 riporta l’elemento all’indice 1, se invece esce 9 quello all’indice 5. Funziona anche con indici negativi.
(
var a = #[1, 0.75, 0.25, 0.33, 0.33, 0.33, 0.5, 0.5], // items
// 0 1 2 3 4 5 6 7 // indici
id = rrand(-5,10),
item = a.foldAt(id);
[id, item]
)
Questi metodi non hanno esclusivamente una valenza informatica ma anche musicale. Infatti come vedremo in seguito potremo utilizzarli per generare e controllare alcuni tipi di variazioni procedurali.
Così come abbiamo visto parlando di scheduling, possiamo richiamare gli items di un Array "a mano" valutando di volta in volta le singole righe di codice, oppure automatizzare il processo sfruttando una caratteristica non ancora illustrata del metodo n.do({}). Sappiamo che questo metodo implica la presenza di una funzione e che all’interno di questa possiamo specificare degli argomenti. Quando una funzione è argomento di un metodo come in questo caso gli argomenti non sono utilizzati come indirizzi ai quali inviare valori dall’esterno ma per recuperare automaticamente informazioni istantanee sullo stato dell'oggetto. Nello specifico di n.do({}) se scriviamo un solo argomento, indipendentemente dal nome che gli diamo, assume valenza di contatore riportando a ogni valutazione della funzione interna il numero di volte che è stata già valutata, partendo da 0. Come ultimo valore riporta come sappiamo già il numero totale di valutazioni effettuate;
(
10.do{
arg ciao; // contatore
ciao.postln // stampa
}
)
Osserviamo la Post window dopo aver valutato il codice: vedremo stampato un numero per riga da 0 a 9 (tutti i passi del loop) e infine 10 che corrisponde al numero totale di valutazioni. Se sostituiamo ora il numero di iterazioni (in questo esempio 10) con un Array, gli argomenti che possiamo specificare sono due e corrispondono a due distinte informazioni:
- il primo argomento (sempre indipendentemente dal nome che gli diamo) restituisce un item alla volta dell’Array seguendo un ordine da sinistra a destra, mentre
- il secondo argomento (sempre indipendentemente dal nome che gli diamo) riporta il numero di iterazioni (contatore).
(
#["a","b","c"].do{arg ciao, miao;
[ciao, miao].postln}
)
L’ultima informazione in questo caso non è il numero totale di valutazioni ma l’Array sul quale abbiamo invocato il metodo. Sebbene l’ordine nella dichiarazione degli argomenti sia prefissato e invariabile (item, contatore), le due informazioni sono indipendenti e legate al nome che gli diamo. Se infatti volessimo postare prima il contatore e dopo l’item potremmo invertire i nomi delle loro etichette nel comando di stampa.
(
#["a","b","c"].do{arg ciao, miao;
[miao, ciao].postln} // nomi invertiti
)
Possiamo anche sostituire i due nomi con la parola riservata ...args che abbiamo già incontrato parlando di TempoClock, ma in questo caso l’ordine non è modificabile.
(
a = #["a","b","c"];
a.do{arg ...args; // argomenti: item, id
args.postln // stampa
}
)
Se invece specifichiamo un solo argomento, otterremo semplicemente un iterazione degli items.
(
a = #["a","b","c"];
a.do{arg biro; // 1 argomento: item
biro.postln
}
)
Le sintassi appena esposte sono funzionali alla lettura completa da sinistra a destra di un Array. Se però volessimo leggerlo in modo parziale o randomico oppure utilizzare i metodi [].clipAt(), [].wrapAt() o [].foldAt() non potremmo farlo in quanto una volta terminata l’iterazione il loop si ferma. Per questo motivo torna molto utile l’argomento che riporta numero di valutazioni della funzione (contatore), che possiamo utilizzare come argomento di [].at() o dei suoi simili:
(
a = #["a","b","c"]; // Array da iterare
n = 10; // numero di iterazioni (da 0 a 9)
n.do{arg biro; // riporta il numero di iterazione a ogni passo
a.at(biro).postln // richiama gli items dagli indici
}
)
Valutando il codice precedente dopo i tre items contenuti nell’Array vedremo stampati nella Post window sette nil e infine il numero 10. In questo modo possiamo utilizzare anche gli altri metodi:
(
a = #["a","b","c","d","e"];
n = 10;
3.do{arg biro;
a.at(biro).postln};
"-----------".postln;
n.do{arg biro;
a.clipAt(biro).postln};
"-----------".postln;
n.do{arg biro;
a.wrapAt(biro).postln};
"-----------".postln;
n.do{arg biro;
a.foldAt(biro).postln};
)
Per realizzare un sequencing possiamo temporizzare i processi di lettura di un Array includendoli in Routine e Task. Di seguito alcuni esempi:
// Richiamando direttamente gli items.
(
var bpm = 100, // bpm
t = TempoClock(bpm/60), // metronomo
dt = #[1,0.75,0.25,0.33,0.33,0.33,0.5,0.5], // tempi delta
r = Routine({
dt.do({arg delta; // items
Synth("sperc"); // suona
delta.postln; // stampa
delta.wait}) // aspetta
});
r.play(t)
)
// Richiamando gli indici con '[].wrapAt(id)' e simili.
(
var bpm = 120,
n = 20, // numero di eventi
t = TempoClock(bpm/60),
dt = #[1,0.75,0.25,0.33,0.33,0.33,0.5,0.5],
r = Routine({
n.do({arg id; // indici
var delta = dt.wrapAt(id);// itera gli items
Synth("sperc"); // suona
[id,delta].postln; // stampa
delta.wait}) // aspetta
});
r.play(t)
)
Come possiamo osservare valutando questo secondo esempio l’argomento di n.do({}) non riporta gli indici dell’Array ma il numero di valutazioni della funzione. Non confondiamoci.
Con questa tecnica possiamo infine sincronizzare tra loro diversi parametri, ognuno memorizzato in un Array differente:
(
var bpm,t,tsec,note,vels,durs,dt,r;
bpm = 150;
t = TempoClock(bpm/60);
tsec = 60/bpm;
note = [90, 100, 98, 97, 96, 93].midicps;
vels = [60, 90, 120, 60, 40, 10]/127;
durs = [0.125, 0.125, 0.5, 0.25, 0.125, 1]*tsec;
dt = [ 0.25, 0.25, 1, 1, 1, 1];
r = Routine({dt.do{arg delta, id;
Synth("sperc",[\freq, note.at(id), // frequenze richiamate come indici
\amp, vels.at(id), // ampiezze richiamate come indici
\dur, durs.at(id) // durate richiamate come indici
]
);
delta.wait} // tempi delta richiamati come items
}).reset.play(t);
)
Determinismo
In questo paragrafo possiamo leggere cosa è una procedura deterministica e come possiamo impiegarla per la composizione di suoni nel tempo Qui invece vedremo come realizzare sequenze di eventi musicali nel tempo in SuperCollider. Teniamo presente un concetto che ripeterò più volte: organizzeremo sequenze di quei parametri del suono che più sono legati alla tradizione musicale occidentale: altezze, intensità, tempi delta e durate ma le stesse tecniche possono essere applicate a qualsiasi altro parametro di qualsiasi tipo di sintesi o elaborazione del suono come vedremo nelle prossime sezioni. Infine sottolineo che in questo Paragrafo scopriremo solo come programmare sequenze nel tempo di valori assoluti senza entrare nel merito di regole, linguaggi e sintassi musicali o sonore che saranno anch'esse affrontate nelle prossime Sezioni. Tutti gli esempi e lo sviluppo degli esercizi saranno eseguiti dal Synth \sperc già utilizzato in precedenza.
Alla fine del Paragrafo precedente abbiamo visto come realizzare una sequenza musicale qualsiasi in libero arbitrio semplicemente aggiungendo nuovi Array, uno per ogni parametro desiderato:

Per comodità abbiamo specificato i valori in unità di misura facilmente interpretabili sia da altri esseri umani che da altri software o interfacce esterne a SuperCollider: frequenze in midinote, ampiezze in velocity (entrambe in valori compresi tra 0 e 127), durate e tempi delta in tempo relativo (frazioni di beat). A questo punto si pone un problema. Infatti come abbiamo appurato qualche riga sopra il Synth "sperc" accetta valori espressi unità di misura differenti da queste. Si rendono necessarie alcune conversioni.
Conversioni di tempo
Come possiamo notare, gli items dell'Array in cui sono specificati i tempi delta sono richiamati uno alla volta all'interno della Routine che genera la sequenza di eventi e che "lavora" al tempo relativo espresso in bpm con TempoClock. Di fatto sono già frazioni del beat. Gli items dell'Array in cui sono specificate le durate invece sono "inviati" al Synth che accetta valori espressi in tempo assoluto (secondi). Si rende dunque necessaria una conversione:
prima calcoliamo il valore in tempo assoluto del beat (unità) attraverso la formula che già conosciamo:
( var bpm, tsec; bpm = 150; tsec = 60/bpm; // beat (1) in tempo assoluto )
poi moltiplichiamo tutti i valori contenuti nell'Array per il risultato ottenuto:
( var bpm, tsec, durs; bpm = 150; tsec = 60/bpm; durs = [0.125, 0.125, 0.5, 0.25, 0.125, 1]*tsec; // frazioni del beat in tempo assoluto )
In questo modo al Synth arriveranno i valori in tempo assoluto calcolati di volta in volta al tempo relativo che esprimeremo in bpm.
Conversioni di altezze o frequenze
Come sappamo le altezze possono essere espresse attraverso differenti unità di misura:
- Midi pitch (60 = Do centrale),
- Hertz (cps),
- Fattori di moltiplicazione delle frequenze in Hertz (ratio),
- Gradi di una scala o serie (0 = nota perno).
Vediamo i principali metodi di SuperCollider che possiamo utilizzare per le conversioni di frequenza:
60.midicps; // midi --> Hz 440.cpsmidi; // Hz --> midi 2.degreeToKey([0,2,5,7]); // il ricevente è l'indice (degree) della scala che spefichiamo come argomento 6.keyToDegree([0,2,3,6]); // il ricevente è il grado relativo tra gli indici 2.midiratio; // midi --> fattore di moltiplicazione 1.6.ratiomidi; // fatt.--> midi 440 * 1.midiratio;
Conversioni di intensità o ampiezze
Compiamo le stesse operazioni per quanto riguarda le intensità:
- Midi velocity (tra 0 e 127),
- Ampiezza lineare (tra 0.0 e 1.0),
- ampiezza quartica (tra 0.0 e 1.0),
- decibels (da -inf a 0).
Vediamo i principali metodi di SuperCollider che possiamo utilizzare per le conversioni delle ampiezze:
64/127; // velocity --> lineare 0.5*127; // lineare --> velocity 0.5.pow(4); // lineare --> quartica 0.0001.ampdb; // lineare --> decibel -80.dbamp; // decibel --> lineare
Pause
Fino a questo punto abbiamo realizzato sequenze di eventi nel tempo ma nessuno di questi era una pausa. In generale, indipendentemente dal software musicale che usiamo ci sono due modi differenti per ottenere pause all'interno di una sequenza di suoni:
- "barare" generando un evento con ampiezza 0 e frequenza fittizia:
( var bpm, t, note, vels,dt,r; bpm = 120; t = TempoClock(bpm/60); note = 72.midicps; vels = [80,80,80,0,80,80,0,80]/127; dt = 0.5; r = Routine({ vels.do({arg vel; Synth("sperc",[\freq, note, \amp, vel]); dt.wait }) }).play(t) )
- utilizzare una combinazione di tempi delta e durate. Se le durate sono inferiori ai tempi delta avremo una pausa tra un evento e
il successivo:
( var bpm,t,note,tsec,durs,dt,r; bpm = 120; t = TempoClock(bpm/60); tsec = 60/bpm; note = 72.midicps; durs = [1, 0.5, 0.25, 0.125, 0.25, 0.5, 1]*tsec; dt = 1; r = Routine({ durs.do({arg dur; Synth("sperc",[\note, note, \dur, dur]); dt.wait }) }).play(t) )
Se invece le durate sono superiori ai tempi delta avremo una sovrapposizione di eventi (polifonia).
( var bpm,t,note,tsec,durs,dt,r; bpm = 120; t = TempoClock(bpm/60); tsec = 60/bpm; note = [72,76,79,84].midicps; durs = [5,4,3,2]*tsec; dt = 1; r = Routine({ durs.do({arg dur,id; Synth("sperc",[\freq, note.at(id), \dur, dur]); dt.wait }) }).play(t) )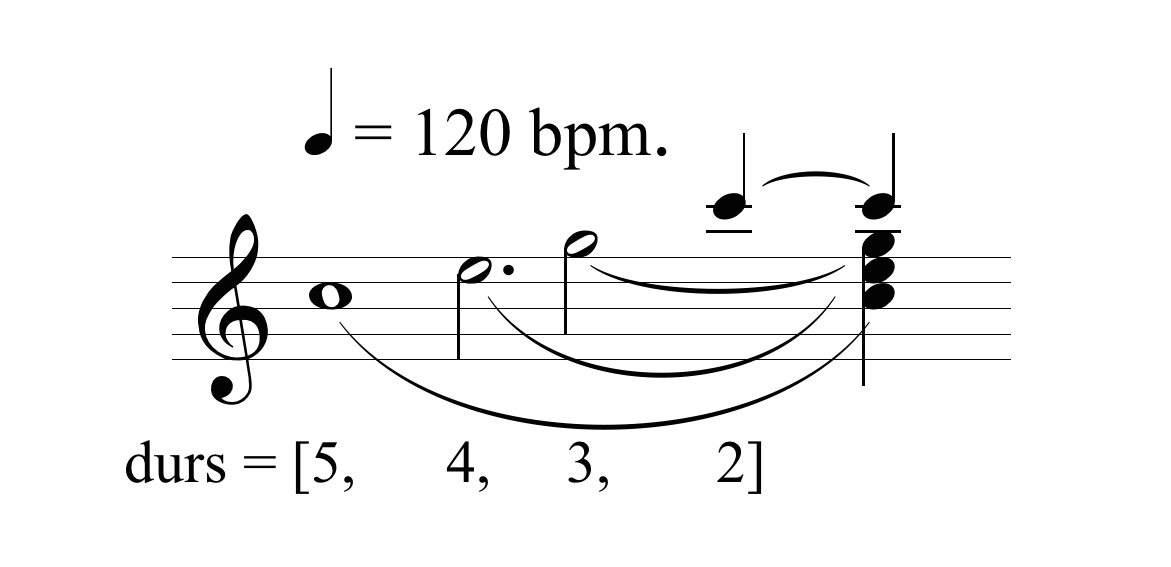
In questo Capitolo non ci dobbiamo preoccupare di questa seconda ipotesi in quanto il Synth "sperc" ha una voice allocation automatica ed è polifonico di default.
Sequenze e insiemi
Nella pratica musicale un Array o una qualunqe collezione di dati può essere pensata e utilizzata in due modi differenti:
una sequenza in cui gli eventi si svolgono in un tempo irreversibile da sinistra a destra uno dopo l'altro, come quelle incontrate fino a questo punto:
( var bpm,t,dt,r; bpm = 100; t = TempoClock(bpm/60); dt = [0.125,0.125,1,0.125,0.125,0.3,0.3,0.3,1]; r = Routine({ dt.do({arg delta, id; [id,delta].postln; // Stampa Synth("sperc"); // Suona delta.wait // Aspetta }) }).reset.play(t) )
un insieme o riserva di eventi dal quale possiamo richiamare i singoli item in svariati modi: in successione, in modo casuale, al contrario, solo in parte, etc.
( var bpm,t,dt,len,r; bpm = 100; t = TempoClock(bpm/60); dt = [0.125,1,0.3]; len = 11; // lunghezza della sequenza in eventi r = Routine({ len.do({arg id; var delta = dt.choose; // Sceglie [id,delta].postln; // Stampa Synth("sperc"); // Suona delta.wait // Aspetta }) }).reset.play(t) )
Questa differenza, nel linguaggio musicale se applicata alle altezze invece che alle durate può coincidere con quella che esiste in generale tra pensiero contrappuntistico e pensiero armonico, orizzontalità vs verticalità:
- un Array descrive una sequenza melodica di altezze o ritmi o intensità, oppure
- un Array descrive uno o più accordi dai quali possiamo derivare una sequenza melodica oppure un insieme di pattern ritmici caratterizzanti.
Accordi
Secondo quanto appena enunciato una sequenza di valori numerici può rappresentare:
sia una sequenza melodica e dunque un pensiero musicale orizzontale contrappuntistico, che in SuperCollider possiamo realizzare semplicemente assegnando ogni singola voce ad una Routine differente
( var bpm, t, dt_a, dt_b, dt_c; bpm = 100; t = TempoClock(bpm/60); dt_a = 0.125!32; dt_b = 0.25!16; dt_c = 0.5!8; Routine({ dt_a.do({arg delta; // VOCE 1 Synth("sperc",[\freq, 88.midicps]); delta.wait}) }).play(t); Routine({ dt_b.do({arg delta; // VOCE 2 Synth("sperc",[\freq, (66+rand2(3)).midicps]); delta.wait}) }).play(t); Routine({ dt_c.do({arg delta; // VOCE 3 Synth("sperc",[\freq, (48+rand2(3)).midicps]); delta.wait}) }).play(t); )
sia un insieme di campi armonici o accordi dai quali estrapolare profili melodici e quindi un pensiero musicale verticale. Vediamo ora come realizzare accordi in SuperCollider. Per farlo ci sono molti modi e strategie di porgrammazione, che dipendono principalmente da come abbiamo programmato il Synth che li deve eseguire. Ad esempio per quello che stiamo utilizzando (\sperc) una buona strategia potrebbe essere quella adottata nel codice seguente ovvero specificare gli accordi sostituendo il singolo valore di pitch con un Array di valori. In seguito, all'interno della Routine dovremo separare i valori singoli dagli Array misurandone il size:
a = 68; // valore singolo a.size; // riporta '0' a = [12,34,56]; // Array a.size; // sicuramente > di 0
Per poi utilizzare un operatore condizionale:
- se il size dell'item == 0 {esegui la singola nota}
- se è > 0 {esegui questa funzione in loop velocissimo n volte tante quanto il numero di note presenti nell'Array, sostituendo automaticamente gli indici}
( var bpm,t,tsec,note,vels,durs,dt,r; bpm = 60; t = TempoClock(bpm/60); tsec = 60/bpm; // conversione unità da tempo relativo a assoluto note = [[90,93], 100, [98,99,102,100], 97, 96, [93,89,87]].midicps; vels = [ 60, 90, 70, 90, 80, 70]/127; durs = [ 0.25, 0.25, 1, 1, 1, 1]*tsec; dt = [ 0.25, 0.25, 1, 1, 1, 1]; r = Routine({dt.do{arg delta, id; var n = note.at(id); // singoli item di 'note' if(n.size==0, // ...se è un valore: {Synth("sperc",[\freq, n, // note singole \amp, vels.at(id), \dur, durs.at(id)]) }, // ...se è un Array: {n.size.do({arg i; // loop (accordi) Synth("sperc",[\freq, n.at(i), \amp, vels.at(id), \dur, durs.at(id)]) }) } ); delta.wait} // tempi delta }).reset.play(t) )
Un Array che comprende al suo interno altri Array è chiamato bidimensionale o meglio un Array 2D
Alea
In questo paragrafo possiamo leggere cosa è una procedura non deterministica e come possiamo impiegarla per la composizione di suoni nel tempo. Qui invece vedremo quali sono gli oggetti di SuperCollider che restituiscono valori pseudocasuali seguendo le diverse modalità già illustrate nel Paragrafo sopracitato. Tutti gli oggetti seguenti operano secondo una distribuzione linerare delle probabilità, le tecniche che seguono procedure stocastiche saranno affrontate in un altro Paragrafo.
Scelta pseudocasuale di un valore booleano. Questo tipo di scelta avviene solamente tra due stati: true/false oppure 0/1.
0.5.coin; // 50% = true, 50% = false 0.5.coin.asInt; // true = 1, false = 0
Un primo esempio di impiego musicale di questa tecnica potrebbe essere la scelta casuale tra suono o silenzio (nota/pausa). Ricordo che tutti gli esempi utilizzano il Synth \sperc che deve essere inviato al Server valutando questo codice.
( // ...poi questo var bpm = 92; TempoClock.new(bpm/60) .sched(0,{ if(0.5.coin==true, {Synth(\sperc,[freq:69.midicps,amp:0.7]); "nota".postln}, {"pausa".postln} ); 0.25 }) )Che in una eventuale partitura per un esecutore "umano" potremmo notare nel modo seguente:

Un secondo esempio invece potrebbe essere l'alternanza casuale tra due note o due suoni:
( var bpm = 60; TempoClock.new(bpm/60) .sched(0,{ if(0.5.coin==true, {Synth(\sperc,[freq:72.midicps,amp:0.6])}, {Synth(\sperc,[freq:77.midicps,amp:0.9])}, ); 0.125 }) )
Scelta pseudocasuale di un valore compreso tra due limiti.
rand(8); // tra 0 e n-1 rand2(1.0) // tra +/- n rrand(20,50); // tra min e max
Nel linguaggio musicale della tradizione occidentale, tipicamente tra due altezze o intensità in quanto il tempo è relativo, misurato e mensurale, il che rende "macchinosa" questa tecnica. Se applicata invece a tecniche di sintesi ed elaborazione del suono (lunghezza del taglio di campioni, ampiezze o frequenze di una sintesi additiva, etc.) può dare risultati espressivi interressanti. Spesso l'applicazione di valori randomici entro due limiti viene utilizzata anche per "umanizzare" i suoni o i gesti musicali generati dalle macchine.

In un primo esempio possiamo affidare al caso la semplice scelta di altezze (in valori MIDI compresi tra 60 e 90) e ampiezze che seguono una scala lineare tra 0.0 e 1.0.
( var bpm = 60; TempoClock.new(bpm/60) .sched(0,{Synth(\sperc,[freq:rrand(60,90).midicps, amp: rand(1.0)]); 0.125 // provate a rendere randomico anche il tempo }); )Un secondo esempio musicale invece può essere dato dallo scegliere un'altezza perno (sia in modo deterministico che indeterministico) e far compiere la scelta pseudocasuale all'interno di un intervallo di deviazione sia positivo che negativo riferito a questa altezza:
( var bpm, nota_p,deviazione; bpm = 60; nota_p = 72; deviazione = 7; TempoClock.new(bpm/60) .sched(0,{var nota = nota_p+rand2(deviazione); Synth(\sperc,[freq:nota.midicps, amp: rand(1.0)]); 0.125 }); )Un terzo esempio può essere dato da una procedura stocastica chiamata Random walk. Ci occuperemo di precedure stocastiche in un altra parte del sito, ma il random walk ci permette una riflessione sullo stato di un sistema. Negli esempi precedenti la probabilità che uscisse un valore piuttosto che un altro tra quelli inclusi nei limiti era ogni volta uguale per tutti i valori (distribuzione uniforme delle probabilità), come se il sistema si "resettasse" ad ogni scelta. In un random walk invece la scelta non è assoluta ma relativa allo stato precedente, ovvero al valore che è stato generato dalla scelta immediatamente precedente. Per meglio comprendere pensiamo al secondo esempio appena esposto: la scelta è compiuta all'interno di un ambito di deviazione relativo ad un valore di riferimento costante (nota perno). Se noi sostituiamo ad ogni scelta questo valore di riferimento con quello ottenuto dalla scelta precedente otteniamo un random walk.
( var bpm, nota_p,passo; bpm = 60; nota_p = 72; passo = 2; TempoClock.new(bpm/60) .sched(0,{var nota = nota_p + rand2(passo); Synth(\sperc,[freq:nota.midicps, amp: rand(1.0)]); nota_p = nota.clip(0,127); // aggiorna la nota perno allo stato corrente 0.125 }); )Scelta pseudocasuale di un valore compreso tra quelli appartenenti ad un insieme.
[87,78,76,45,23].choose; [0.1,0.9,1].choose; 1/[2,3,4,8].choose;
In questo caso la scelta non avverrà tra tutti i valori compresi entro due limiti ma solo tra quelli compresi in un insieme.
( var bpm = 120; TempoClock.new(bpm/60) .sched(0,{var alt,acc,sudd; alt = [62,70,68,74,63]; // insieme delle altezze acc = [0.1, 1.0]; // insieme delle ampiezze sudd = 1/[1, 2, 4, 8, 16]; // insieme dei tempi delta Synth(\sperc,[freq:alt.choose.midicps, amp: acc.choose]); sudd.choose }); )Notiamo che nell'esempio appena esposto a differenza delle procedure deterministiche i tre Array hanno lunghezze diverse, in quanto non c'è una lettura sincronizzata da sinistra a destra o viceversa. Questa tecnica rappresenta inoltre un pensiero musicale speculare rispetto alle precedenti e un diverso modo di programmare. Nelle tecniche precedenti la scelta dei valori è avvenuta in tempo reale, ovvero nel momento in cui è stata effettuata la scelta si è prodotto anche il suono. Per contro a livello informatico possiamo prima generare del materiale che, nel caso del linguaggio musicale consiste in Array o liste di valori. Il primo caso non implica alcuna regola di un linguaggio musicale, se non la rappresentazione dell'algoritmo randomico:
( var bpm; bpm = 120; t = TempoClock.new(bpm/60); r = Routine.new({ inf.do({var note = rrand(60,71); // ambito Synth(\sperc,[freq:note.midicps, amp: 0.5]); 0.25.wait }) }).play(t) )Nel secondo caso invece è sottointesa un'organizzazione sintattico/lessicale che precede la scelta del singolo elemento, per capirci nel caso delle altezze l'Array corrisponde ad una scale musicale o a un modo con tutto ciò che ne deriva, anche se come in questo caso (scala cromatica) a livello percettivo non c'è alcuna differenza.
( var items, bpm; items = [60,61,62,63,64,65,66,67,68,69,70,71]; // scala cromatica bpm = 120; t = TempoClock.new(bpm/60); r = Routine.new({ inf.do({var note = items.choose; Synth(\sperc,[freq:note.midicps, amp: 0.5]); 0.25.wait }) }).play(t) )
Infine soffermiamoci su una possibile esigenza musicale comune a tutti gli algoritmi di scelta pseudocasuale appena illustrati: il voler richiamare tutti i valori in un ambito o appartenenti ad un insieme una volta sola, senza ripetizioni come ad esempio la generazione pseudo-casuale delle altezze di una serie dodecafonica. In questo caso siamo obbligati ad utilizzare l'ultima tecnica illustrata in quanto dobbiamo:
creare un insieme ordinato di tutti i valori compresi in un ambito sotto forma di Array o lista
a = [60,61,62,63,64,65,66,67,68,69,70,71]
modificare randomicamente le loro posizioni all'interno dell'Array o della lista
a = [60,61,62,63,64,65,66,67,68,69,70,71].scramble
richiamare gli indici dell'Array o lista non in modo pseudo-casuale ma consequenziale da sinistra verso destra oppure viveversa.
( var a, bpm; a = [60,61,62,63,64,65,66,67,68,69,70,71].scramble; bpm = 120; t = TempoClock.new(bpm/60); r = Routine.new({ a.do({arg item; Synth(\sperc,[freq:item.midicps, amp: 0.5]); 0.25.wait }) }).play(t) )
Se invece della scelta pseudocasuale tra due limiti volessimo compiere la stessa operazione tra i valori di un insieme dovremmo compiere le stesse operazioni non sull'Array degli items ma su un Array degli indici sottointesi:
(
var items, idx, bpm;
items = [98,100,76,73,89,103]; // altezze
idx = [0, 1, 2, 3, 4, 5 ].scramble; // indici
bpm = 120;
t = TempoClock.new(bpm/60);
r = Routine.new({
idx.do({arg id;
Synth(\sperc,[freq:items.at(id).midicps,
amp: 0.5]);
0.25.wait
})
}).play(t)
)
Interpolazioni
Vai da a a b in tot
Oltre che variare dinamicamente dall'Interprete il singolo valore, nei controlli di alcuni parametri musicali avremo bisogno di generare delle interpolazioni di diverso tipo per risolvere esigenze tecniche o musicali che rispondano al seguente concetto:
parti da 'a' e vai a 'b' in 'n' passi piccoli o grandi
In musica nella descrizione dei parametri di alto livello il numero di passi è generalmente sostituito dal tempo, anche se come vedremo è un parametro di cui tener conto nelle operazioni matemetiche da effettuare.
parti da 'a' e vai a 'b' in tot secondi con passi piccoli o grandi

Per quanto riguarda le frequenze ad esempio si tratta di un concetto che esprime un glissato o un qualche tipo di scala che suddivide un intervallo, per le ampiezze un crescendo o diminuendo mentre per il panning i movimenti della sorgente, etc. Possiamo realizzare questo concetto sia con segnali generati da UGens dedicate all'interno del Server come abbiamo fatto per esempio per il portamento (.lag() e suoi simili) sia nell'Interprete temporizzando e automatizzando alcune operazioni matematiche. Per ora occupiamoci di quest'ultimo caso passo dopo passo.
definiamo i parametri di alto livello dichiarandoli come argomeni di una funzione:
parti da 200 e vai a 800 in 3 secondi seguendo una curva lineare con passi piccoli (indice di definizione uguale a 0.01)
( ~rampa = {arg a = 200, // inizio b = 800, // fine dur = 3, // durata defId = 0.01; // indice di definizione tra 0.1 (10 passi), 0.01 (100 passi) e 0.001 (1000 passi) } )calcoliamo l'intervallo assoluto tra a e b:
( ~rampa = {arg a=200,b=800,dur=3,defId=0.01; var range; range = abs(a-b); } ) ~rampa.value; // risultato...calcoliamo il numero di passi utilizzando come valori limite 0 e 1 perchè quando dovremo generare curve non linerari questo è l'unico intervallo che mantiene il valore di arrivo invariato:
( ~rampa = {arg a=200,b=800,dur=3,defId=0.01; var range,nPassi; range = abs(a-b); nPassi = 1/defId; // nPassi = defId.reciprocal; // alternativa... } ) ~rampa.value; // risultato...Volendo possiamo definire direttamente in modo assoluto il numero di passi invece che un indice di definizione relativo, ma questa rimane una scelta personale.
creiamo un Array i cui items corrispondono ai valori di tutti i passi compresi tra il valore di partenza e quello di arrivo sotto forma di onsets:
- invochiamo sull'Array il metodo [].interpolation() che realizza in n passi un'interpolazione lineare tra due valori (in questo caso tra 0 e 1 per la stessa ragione illustrata nel punto precedente).
- riscaliamo i valori nel range compreso tra a e
calcoliamo il tempo delta tra i passi in secondi dividendo la durata del passaggio per il numero di passi:
( ~rampa = {arg a=200,b=800,dur=3,defId=0.01; var range,nPassi,aPasso,dPasso; range = abs(a-b); nPassi = 1/defId; aPasso = Array.interpolation(nPassi,0,1) .normalize(a,b); dPasso = dur/nPassi; } ) ~rampa.value; // risultato...richiamiamo i singoli valori dell'Array nel tempo con il metodo n.do() inserito in una Routine:
( ~rampa = {arg a=200,b=800,dur=3,defId=0.01; var range,nPassi,aPasso,dPasso; range = abs(a-b); nPassi = 1/defId; aPasso = Array.interpolation(nPassi,0,1) .normalize(a,b); dPasso = dur/nPassi; Routine.new({ aPasso.do({arg item; var val; val = item; val.postln; // lo stampa dPasso.wait // tempo delta tra i passi }) }).play } ) ~rampa.value(200,800,3,0.01); // incremento ~rampa.value(450,100,1,0.01); // decremento ( ~rampa.value(rand(1000).postln, // random... rand(1000).postln, rrand(0.1,3),0.01); )
(
~rampa = {arg a=200,b=800,dur=3,defId=0.01;
var range,nPassi,aPasso;
range = abs(a-b);
nPassi = 1/defId;
aPasso = Array.interpolation(nPassi,0,1) // array tra 0 e 1
.normalize(a,b); // riscala
}
)
~rampa.value; // risultato...
Vai a b in tot
Una variante del pensiero (e del codice) precedente è rappresentata dalla seguente situazione:
dal valore che hai vai a 'b' in tot secondi con passi piccoli o grandi
Rispetto al codice precedente basterà eliminare l'argomento a (il valore iniziale) e dichiararlo come variabile al di fuori della funzione, assegnandogli un valore iniziale per permettere di calcolare il range della prima valutazione ed aggiornare il suo contenuto con l'ultimo item letto dal loop nella Routine:
(
var a=0; // dichiarato al di fuori dela funzione
~rampa = {arg b=100,dur=1,defId=0.01;
var range,nPassi,aPasso,dPasso;
range = abs(a-b);
nPassi = 1/defId;
aPasso = Array.interpolation(nPassi,0,1)
.normalize(a,b);
dPasso = dur/nPassi;
Routine.new({
aPasso.do({arg item;
a = item; // aggiorna il valore iniziale
a.postln;
dPasso.wait
})
}).play
}
)
~rampa.value(800,3,0.01); // incrementa
~rampa.value(100,1,0.1); // decrementa
~rampa.value(rand(1000).postln,rrand(0.1,3),0.1); // random
Curve non lineari
Negli esempi precedenti le interpolazioni erano di tipo lineari, ovvero il delta tra i passi rimaneva costante per tutta la rampa. Con una piccola aggiunta nel codice illustrato possiamo generare anche interpolzaioni con curve diverse:
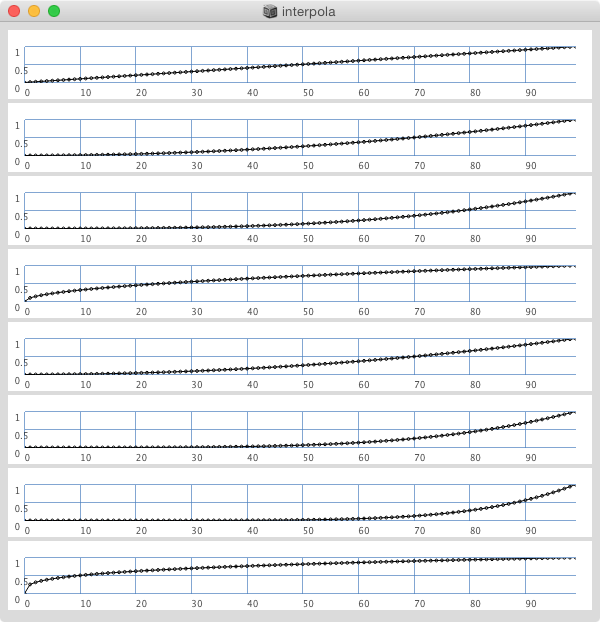
(
var n,lin,scale;
n = 100;
lin = Array.interpolation(n,0,1);
scale = [lin,
lin.squared,
lin.cubed,
lin.sqrt,
lin.pow(2),
lin.pow(4),
lin.pow(6),
lin.pow(0.3)
].plot("interpola",600@600,true)
.plotMode_(\plines)
)
Dobbiamo dunque:
- generare un'interpolazione lineare con valori compresi in un abito tra 0 e 1
- modificare eventualmente la curva
- riscalare i valori in un ambito compreso tra partenza e arrivo
(
var a=0; // dichiarato al di fuori dela funzione
~rampa = {arg b=100,dur=1,defId=0.01;
var range,nPassi,aPasso,dPasso;
range = abs(a-b);
nPassi = 1/defId;
aPasso = Array.interpolation(nPassi,0,1) // Array tra 0 e 1
.squared // curva
.normalize(a,b); // riscala
dPasso = dur/nPassi;
Routine.new({
aPasso.do({arg item;
a = item; // aggiorna il valore iniziale
a.postln;
dPasso.wait
})
}).play
}
)
~rampa.value(800,3,0.01); // incrementa
~rampa.value(100,1,0.1); // decrementa
~rampa.value(rand(1000).postln,rrand(0.1,3),0.1); // random
Integriamo ora le rampe nel codice che abbiamo utilizzato per l'invio del singolo valore, se non vogliamo alcuna rampa basta fissare il tempo a 0.
(
var inizio=0; // operazioni di init
// ------------------------------ SynthDef e Synth
SynthDef(\ksig,
{arg freq=400,smooth=0.02;
var sig, port;
port = freq.lag(smooth); // abbreviazione sintattica
sig = SinOsc.ar(port);
Out.ar(0,sig)
}
).add;
{~synth = Synth(\ksig)}.defer(0.1);
// ------------------------------ Operazioni di basso livello
~ksynth = {arg fine=100,dur=1,defId=0.01,smth=0.02; // aggiunto smth
var range,nPassi,aPasso,dPasso;
range = abs(inizio-fine);
nPassi = 1/defId;
aPasso = Array.interpolation(nPassi,0,1).pow(4).normalize(inizio,fine);
dPasso = dur/nPassi;
Routine.new({
aPasso.do({arg item;
~synth.set(\freq,item,\smooth,smth); // al Synth
inizio = item; // aggiorna l'inizio
dPasso.wait
})
}).play;
};
)
// ------------------------------ Controllo esterno dei parametri
~ksynth.value(800,3,0.01); // incrementa
~ksynth.value(100,1,0.1); // decrementa
~ksynth.value(rrand(300,1000).postln,rrand(0.1,3),[0.1,0.01,0.001].choose); // random
~ksynth.value(800,0,0.01); // senza rampa